






发布于:2020-01-16
本文总阅读量:126





在 KubeSphere 安装 Orion vGPU 使用 TensorFlow 运行深度学习训练
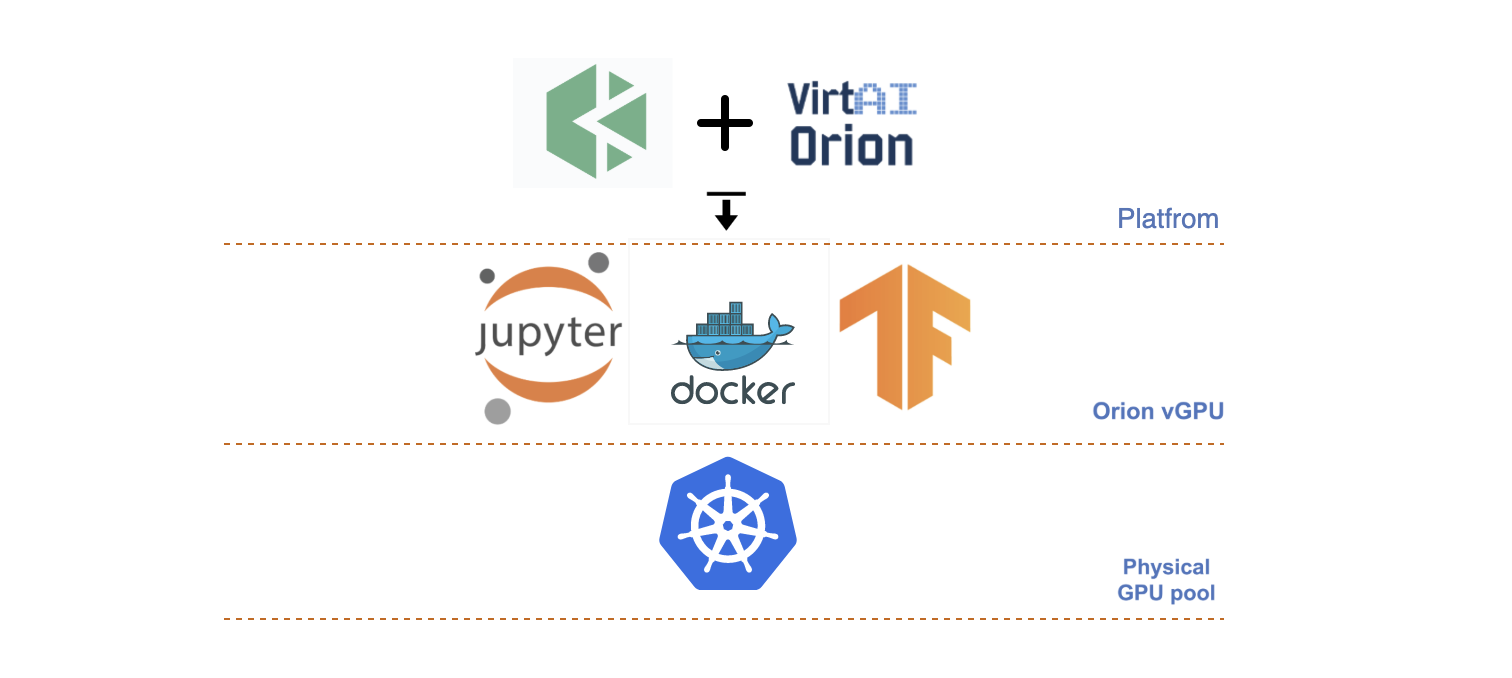
概览
本文将使用 KubeSphere 容器平台,在 Kubernetes 上部署 Orion vGPU 软件 进行深度学习加速,并基于 Orion vGPU 软件使用经典的 Jupyter Notebook 进行模型训练与推理。
在开始安装 Orion vGPU 和演示深度学习训练之前,先简单了解一下,什么是 vGPU 以及什么是 Orion vGPU。
什么是 vGPU
vGPU 又称 虚拟 GPU,早在几年前就由 NVIDIA 推出了这个概念以及相关的产品。vGPU 是通过对数据中心(物理机)的 GPU 进行虚拟化,用户可在多个虚拟机或容器中 共享该数据中心的物理 GPU 资源,有效地提高性能并降低成本。vGPU 使得 GPU 与用户之间的关系不再是一对一,而是 一对多。
为什么需要 vGPU
随着 AI 技术的快速发展,越来越多的企业开始将 AI 技术应用到自身业务之中。目前,云端 AI 算力主要由三类 AI 加速器来提供:GPU,FPGA 和 AI ASIC 芯片。这些加速器的优点是性能非常高,缺点是 成本高昂,缺少异构加速管理和调度。大部分企业因无法构建高效的加速器资源池,而不得不独占式地使用这些昂贵的加速器资源,导致 资源利用率低,成本高。
以 GPU 为例,通过创新的 vGPU 虚拟化技术,能够帮助用户无需任务修改就能透明地共享和使用数据中心内任何服务器之上的 AI 加速器,不但能够帮助用户提高资源利用率,而且可以 极大便利 AI 应用的部署,构建数据中心级的 AI 加速器资源池。
什么是 Orion vGPU
Orion vGPU 软件由 VirtAI Tech 趋动科技 开发,是一个 为云或者数据中心内的 AI 应用、CUDA 应用提供 GPU 资源池化、GPU 虚拟化能力 的系统软件。通过高效的通讯机制连接应用与 GPU 资源池,使得 AI 应用、CUDA 应用可以不受 GPU 物理位置的限制,部署在云或者数据中心内任何一个 物理机、Container 或者 VM 内。
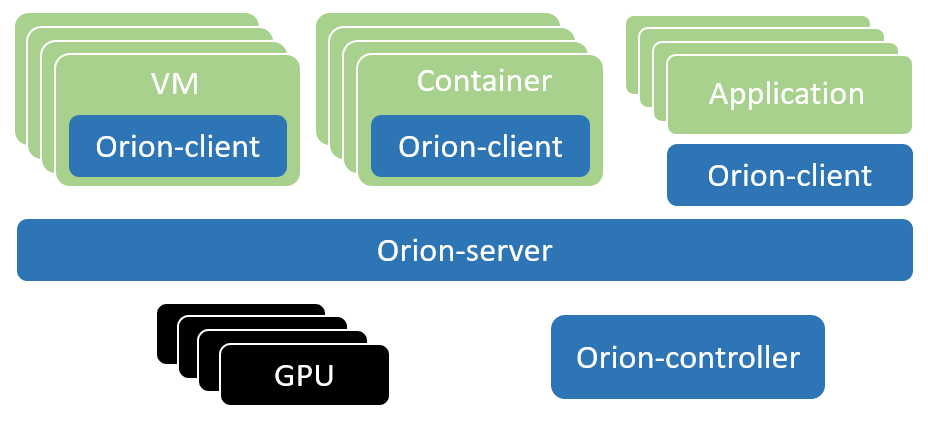
Orion vGPU 软件架构
由于我们将在 KubeSphere 容器平台上部署 Orion vGPU 软件至 Kubernetes,在部署前我们先简单了解一下 Orion vGPU 的软件架构。
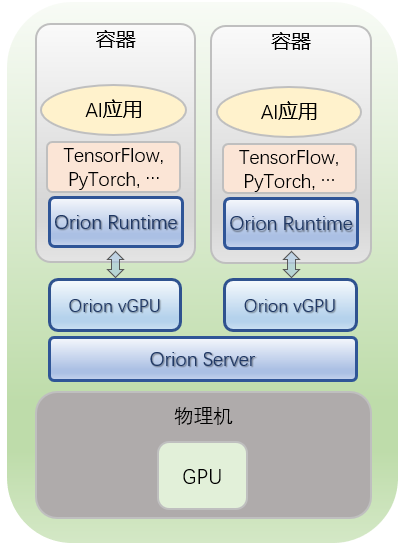
Orion Client
Orion Client 为一个运行时环境,模拟了 NVidia CUDA 的运行库环境,为 CUDA 程序提供了 API 接口兼容的全新实现。通过和 Orion 其他功能组件的配合,为 CUDA 应用程序虚拟化了一定数量的虚拟 GPU(Orion vGPU)。由于 Orion Client 模拟了 NVidia CUDA 运行环境,因此 CUDA 应用程序可以透明无修改地直接运行在 Orion vGPU 之上。
Orion Controller
Orion Controller 是一个长期运行的服务程序,其负责整个 GPU 资源池的资源管理。其响应 Orion Client 的 vGPU 请求,并从 GPU 资源池中为 Orion Client 端的 CUDA 应用程序分配并返回 Orion vGPU 资源。该组件可以部署在数据中心任何网络可到达的系统当中,每个资源池部署一个 Orion Controller。资源池的大小取决于 IT 管理的需求,可以是整个数据中心的所有 GPU 作为一个资源池,也可以每个 GPU 服务器作为一个独立的资源池。可以认为它就像一个中介,帮忙沟通 Orion Client 和 Server。
Orion Server
该组件为一个长运行的系统服务,负责 GPU 资源化的后端服务。Orion Server 部署在每一个物理 GPU 服务器上,接管本机内的所有物理 GPU。Orion Server 通过和 Orion Controller 的交互把本机的 GPU 加入到由 Orion Controller 管理维护的 GPU 资源池当中。
当 Orion Client 端应用程序运行时,通过 Orion Controller 的资源调度,建立和 Orion Server 的连接。Orion Server 为其应用程序的所有 CUDA 调用提供一个隔离的运行环境以及真实 GPU 硬件算力。
场景演示
Orion vGPU 的使用包括以下三类场景:
- 场景一:Docker 容器中使用本地节点 GPU 资源
- 场景二:KVM 虚拟机中使用本地节点 GPU 资源
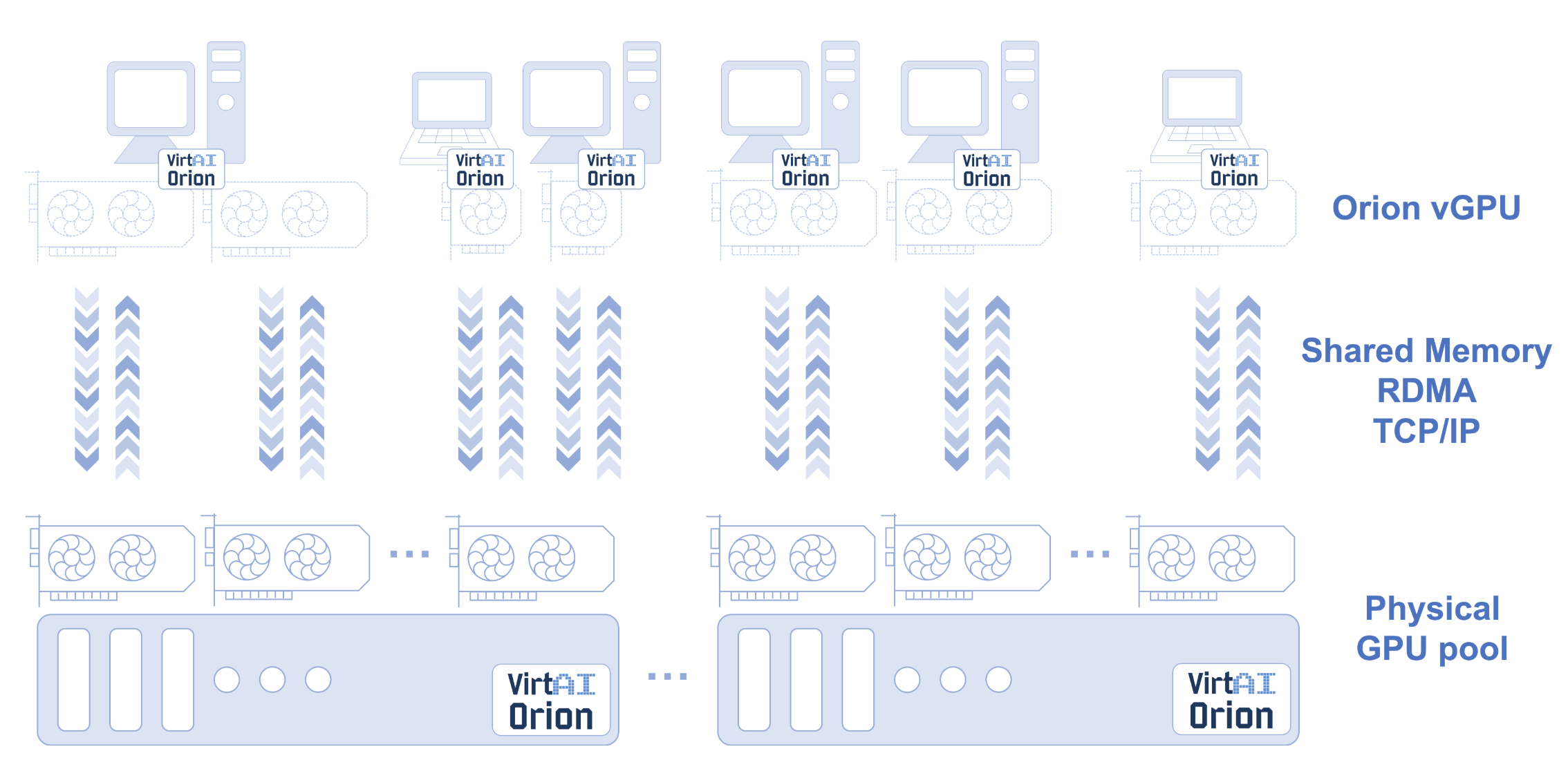
- 场景三:在没有 GPU 的节点上使用远程节点上的 GPU 资源
本文仅对场景一进行演示说明,该场景非常适用于教学及推理场景,后续的文章会对场景三说明如何通过 RDMA 使用远程节点 GPU 资源。
准备 GPU 节点并安装 NVIDIA 驱动和插件
假设您已有 KubeSphere 集群环境,那么可参考 KubeSphere 官方文档扩容一个 GPU 主机作为新的 GPU 节点。本文使用了一台 Ubuntu 18.04 的 GPU 节点通过 KubeSphere 加入了 Kubernetes 集群,并在 GPU 节点安装 NVIDIA 驱动和 NVIDIA Docker 插件,在本文中暂不对该步骤进行详细说明。
安装 Orion vGPU 软件
通过安装 Orion vGPU 软件,容器得以使用 Orion vGPU 资源加速计算。安装完成后,我们将会在容器中运行与测试 TensorFlow 的部分深度学习训练。
如下我们可以使用 KubeSphere 在 Kubernetes 之上容器化部署 Orion vGPU 的三个组件以及它的 Kubernetes Device Plugin。
安装 Orion Controller
在上述已经对 Orion Controller 进行过介绍,它可以部署在集群的任意节点。一般说来,会通过选择器让 Controller 运行在指定的节点上,从而把 Controller 的 IP 地址确定下来。本文为了配置简单,仅安装在了 GPU 物理节点上:
(1)代码克隆到集群中任意主机节点本地。
$ git clone https://github.com/virtaitech/orion
(2)部署 Orion Controller,默认只部署一份 Orion Controller:
$ cd orion/orion-kubernetes-deploy $ vi deploy-controller.yaml
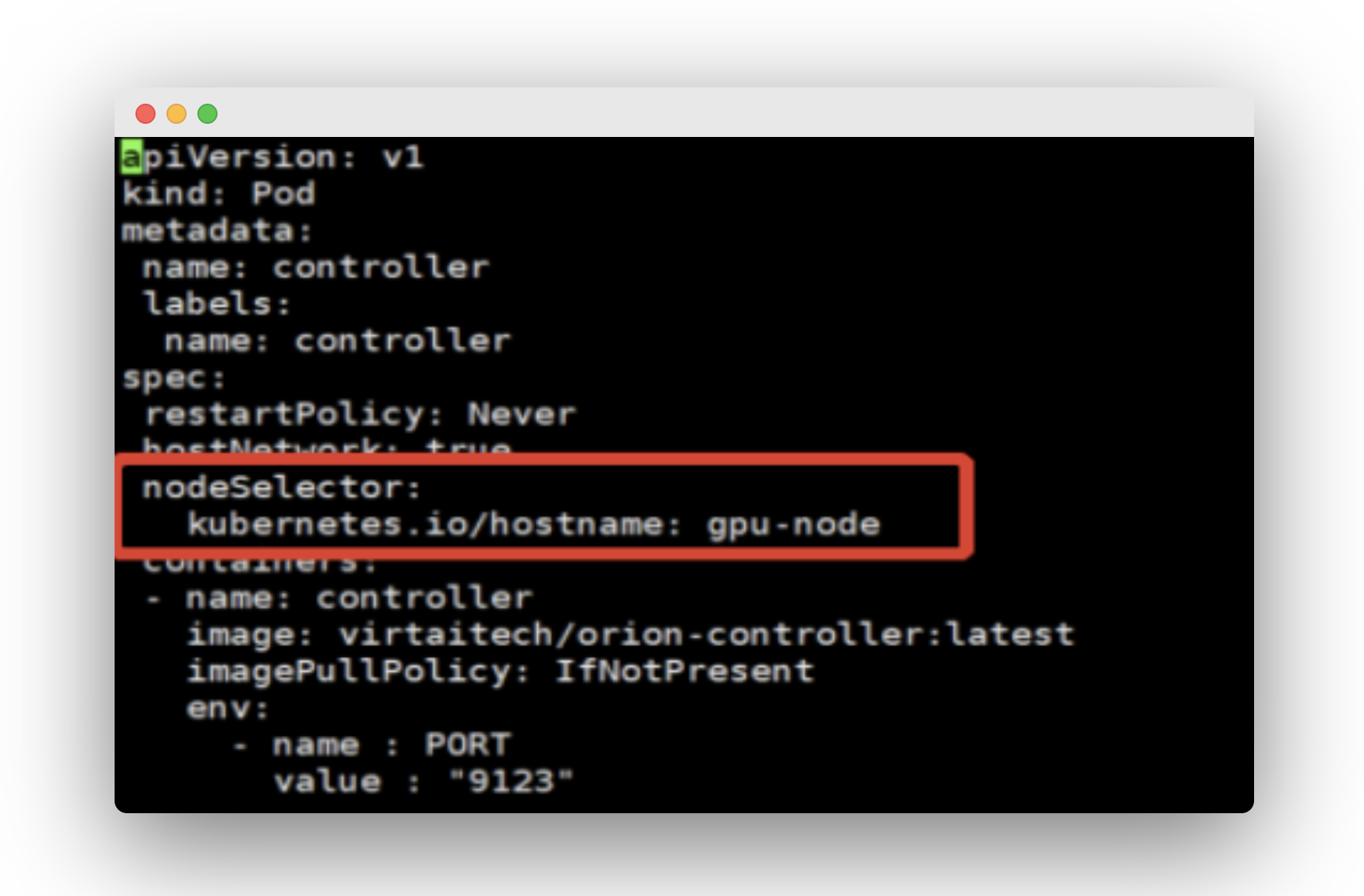
添加节点选择器,如上图,保存。然后执行如下命令部署 Controller:
$ kubectl create -f deploy-controller.yaml
执行完成后在 KubeSphere 界面的 default 项目中可以看到 Controller 的 Pod:

安装 Orion Kubernetes Device Plugin
Orion Kubernetes device plugin 是符合 Kubernetes device plugin 接口规范的设备扩展插件。配合 Orion GPU 可以无缝地在一个 Kubernetes 集群里添加 Oiron vGPU 资源,从而在部署应用的时候,在容器中使用 Orion vGPU。
如下,修改 deploy-plugin.yaml 文件,添加节点选择器,使 Device Plugin 将以 DaemonSet 安装在物理 GPU 节点上。
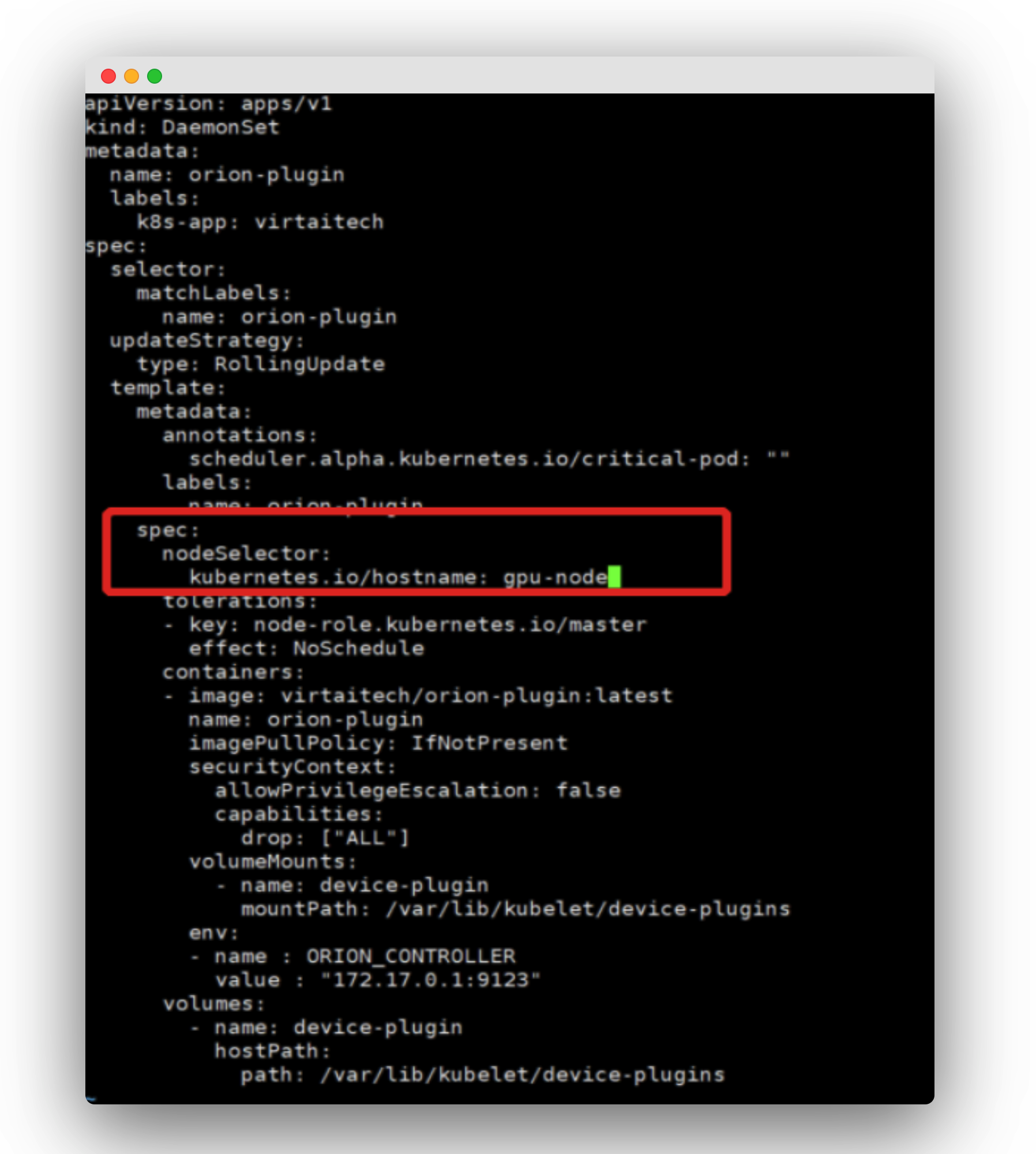
$ kubectl create -f deploy-plugin.yaml
执行完成后,等待一段时间,在 KubeSphere 界面的 default 项目中可以看到 deploy-plugin 的 Pod。

安装 Orion Server
Orion Server 将在物理 GPU 节点以 DaemonSet 形式部署,以部署支持 CUDA 10.0 的 Orion Server 为例。
$ vi deploy-server-cuda10.0.yaml
添加节点选择器,使 Orion Server 安装在物理 GPU 节点上。
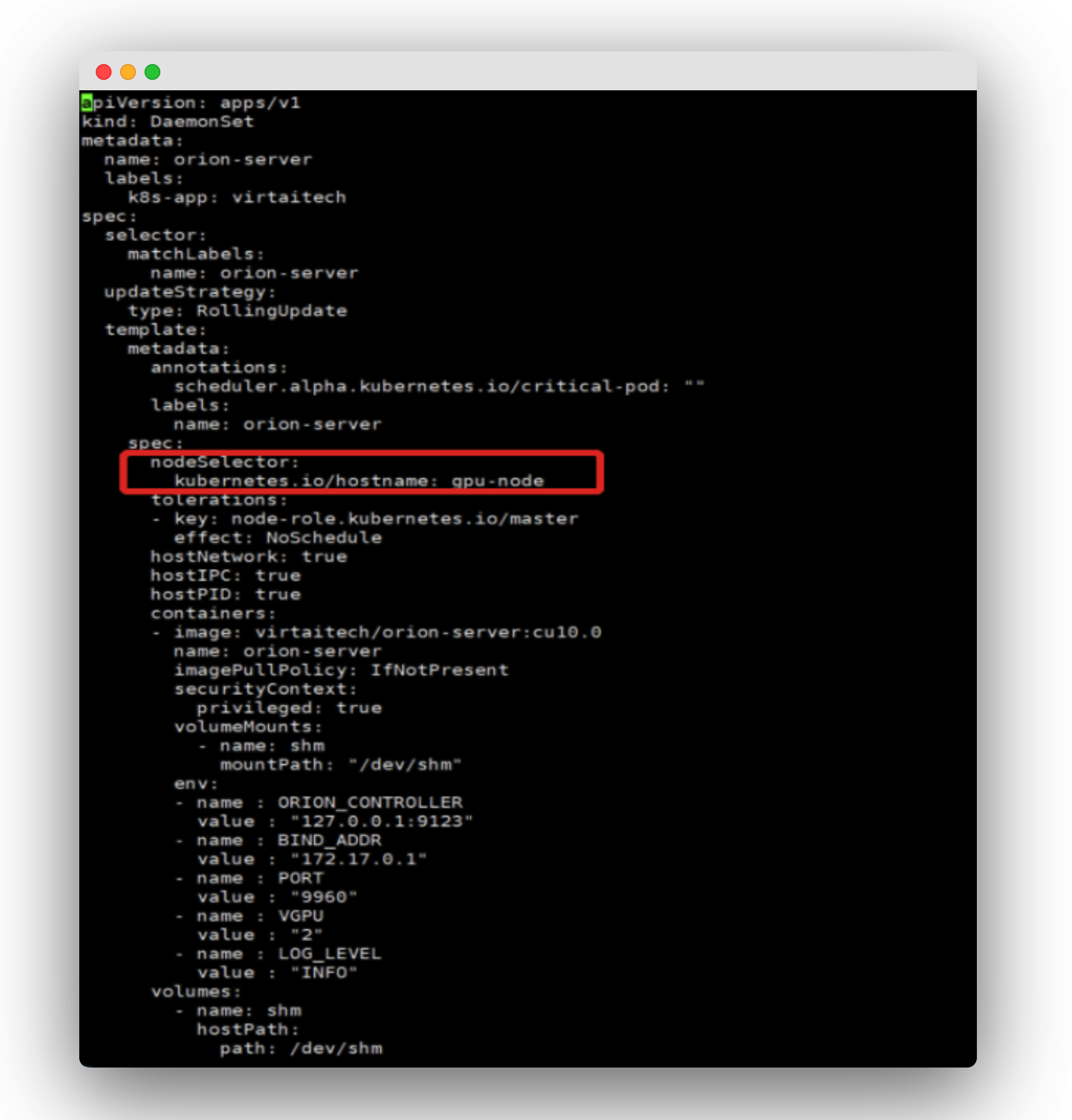
修改后保存即可执行安装:
kubectl create -f deploy-server-cuda10.0.yaml
执行完之后,等待一段时间,在 KubeSphere 界面的 default 项目中可以看到 orion-server 的 Pod。

安装 Orion Client 应用
Orion Client 将安装在物理 GPU 节点,并且使用一个 Jupyter Notebook 作为 Client 应用来使用 vGPU。在 deploy-client.yaml 中添加标签,并且参考如下修改 args:
- resource limit: 可以设置应用能使用的 virtaitech.com:gpu 的数目;
- ORION_GMEM:容器内应用申请的 vGPU 显存大小。
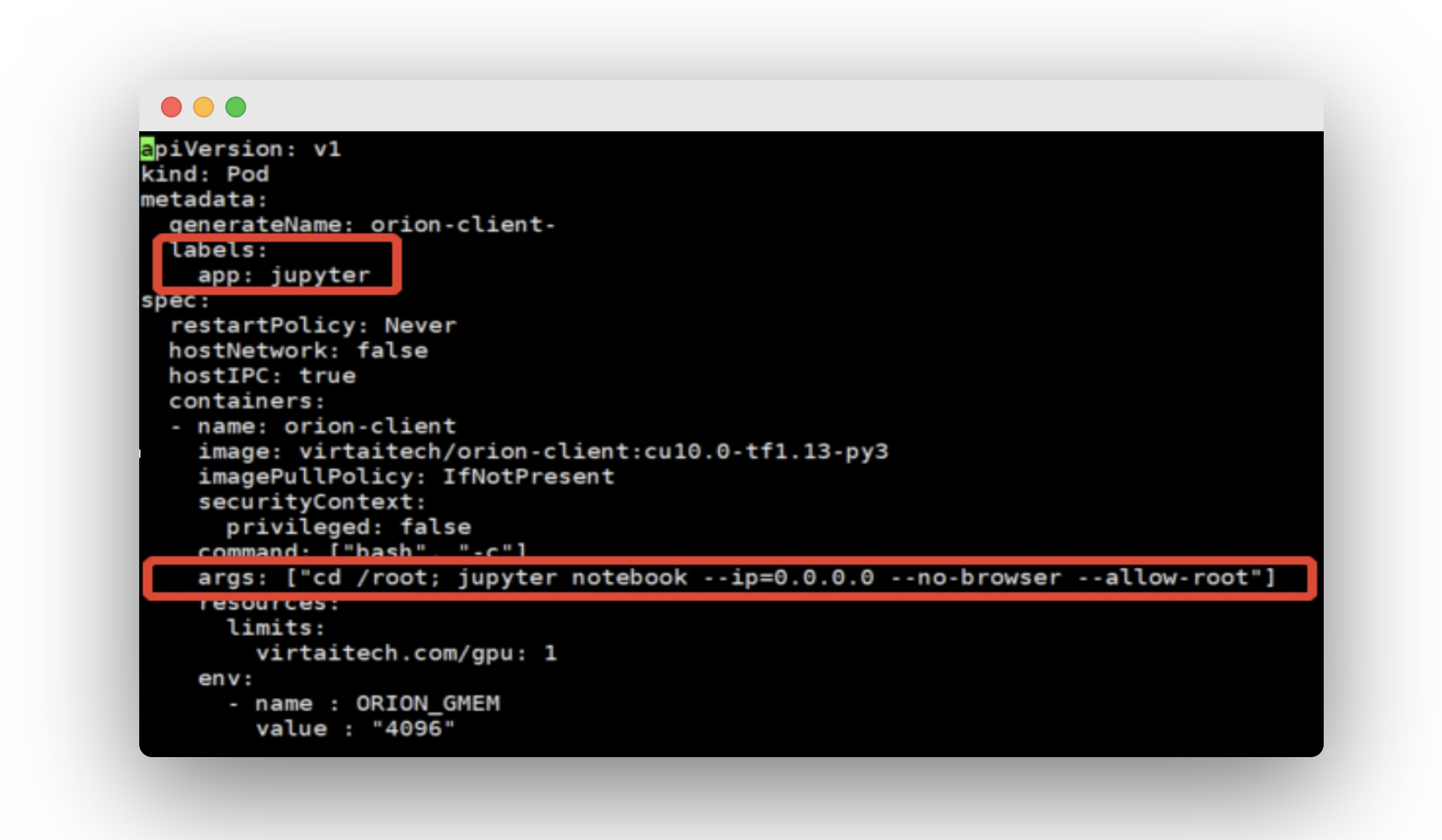
$ kubectl create -f deploy-client.yaml
执行完之后,等待一段时间,default 项目中可以看到 orion-client 的 Pod。

新建一个 deploy-service.yaml 文件用来为 orion-client 创建服务,内容如下:
kind: Service apiVersion: v1 metadata: name: orion-client labels: app: jupyter annotations: kubesphere.io/serviceType: statelessservice spec: ports: - name: tcp-8888 protocol: TCP port: 8888 targetPort: 8888 nodePort: 30110 selector: app: jupyter type: NodePort externalTrafficPolicy: Cluster
其中 labels 与 deploy-client.yaml 中的 Pod 一致,NodePort 为需要暴露的外网服务 然后执行如下命令创建服务:
kubectl create -f deploy-service.yaml
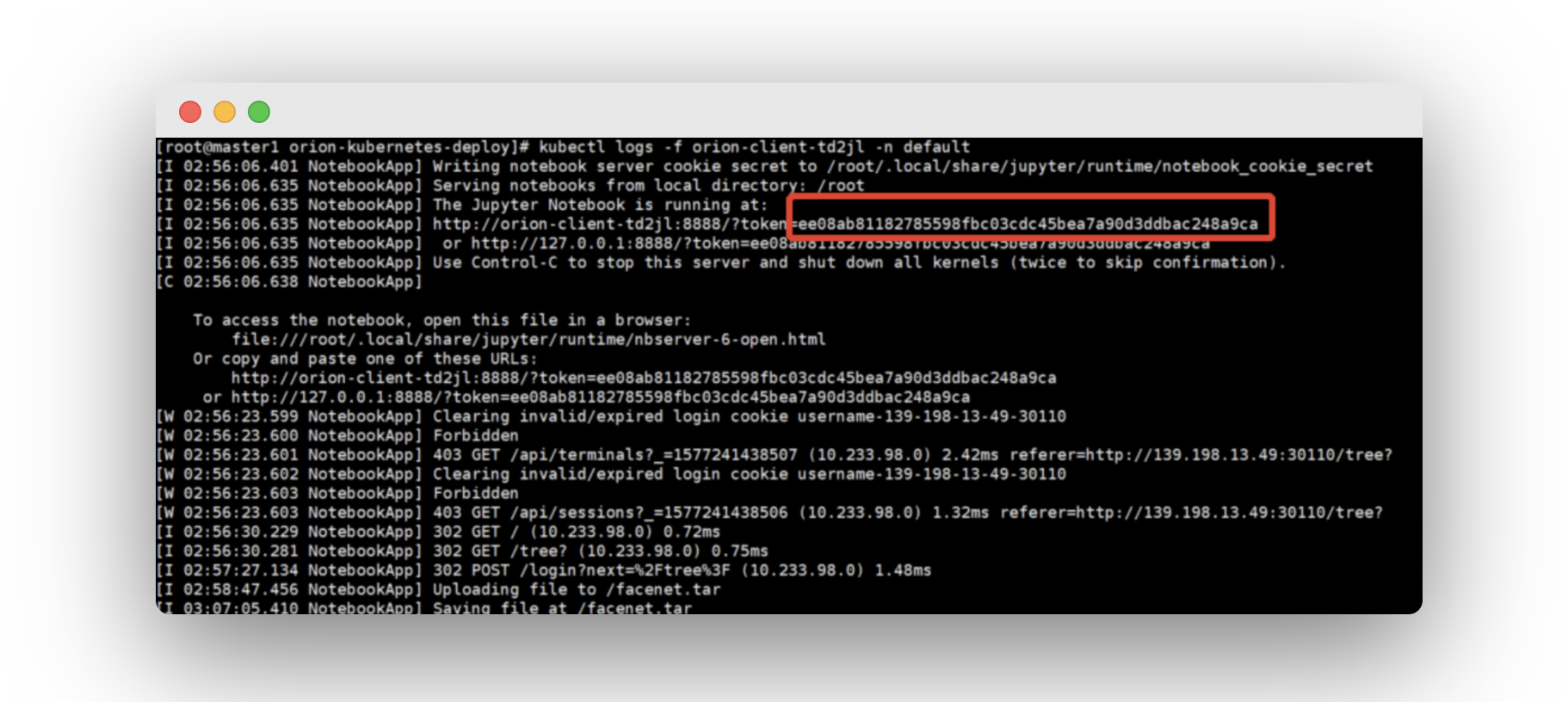
此时可通过外网访问 Jupyter Notebook。查看 orion-client 的日志拿到 token,即可登录 Jupyter Notebook。
训练一个简单的 CNN 模型
以下将在 Jupyter Notebook 训练一个简单的 CNN 模型实现 mnist 手写数字分类。
- 在 Jupyter Notebook 页面点击
new-python3。
- 将
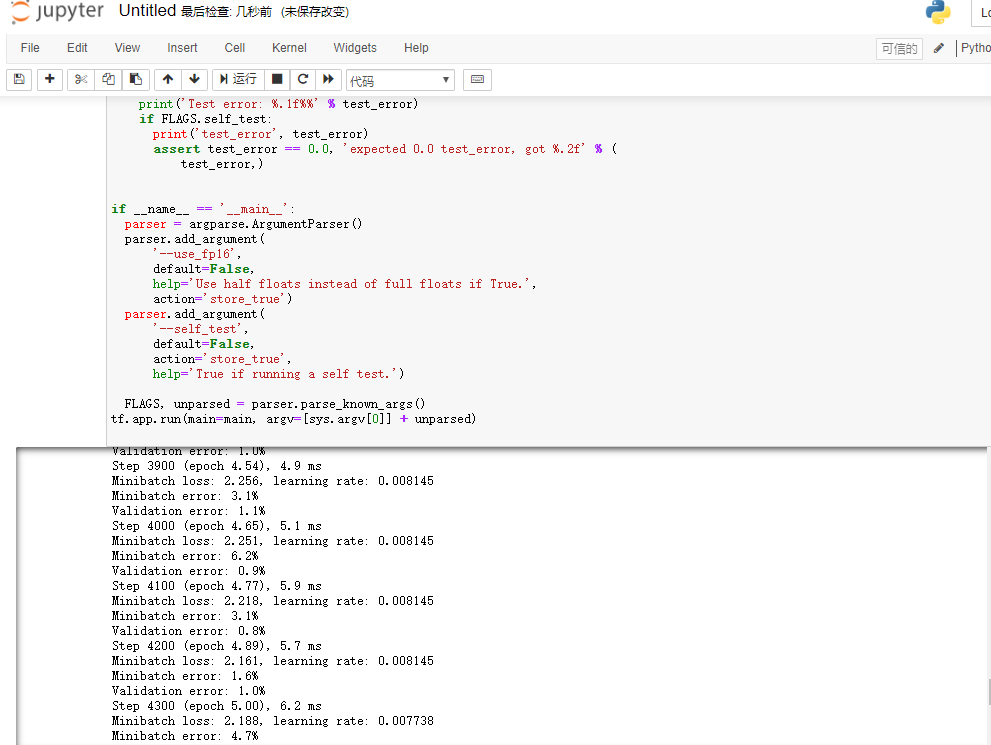
mnist.txt文件中的内容拷贝到上面新建的文件中。鼠标放到代码上,点击运行,运行结果如下:
提示:mnist.txt 文件下载地址:https://kubesphere-docs.pek3b.qingstor.com/files/AI/mnist.txt
- 训练的过程中,我们可以在宿主机上通过 nvidia-smi 工作监视物理 GPU 的使用情况:
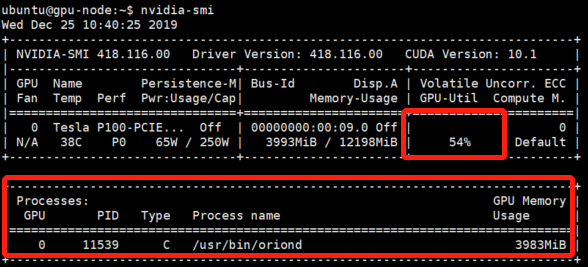
- 从图中可以看到,真正使用物理 GPU 的进程是 Orion Server 的服务进程
/usr/bin/oriond,而不是容器中正在执行 TensorFlow 任务的 Python 进程。这表明容器中的应用程序使用的是 Orion vGPU 资源,对物理 GPU 的访问完全由 Orion Server 所接管。
GPU 深度学习训练测试:人脸识别
- 在 Jupyter 页面上传
facenet.tar文件:
提示:facenet 下载地址: https://kubesphere-docs.pek3b.qingstor.com/files/AI/facenet.tar

- 进入
orion-client容器:
$ kubectl exec -it orion-client-td2jl -n default /bin/bash
- 安装 Python 依赖包:
$ pip3 install scikit-image==0.10 $ pip3 install numpy==1.16.0
- 解压文件 facenet.tar 文件:
$ tar xvf facenet.tar
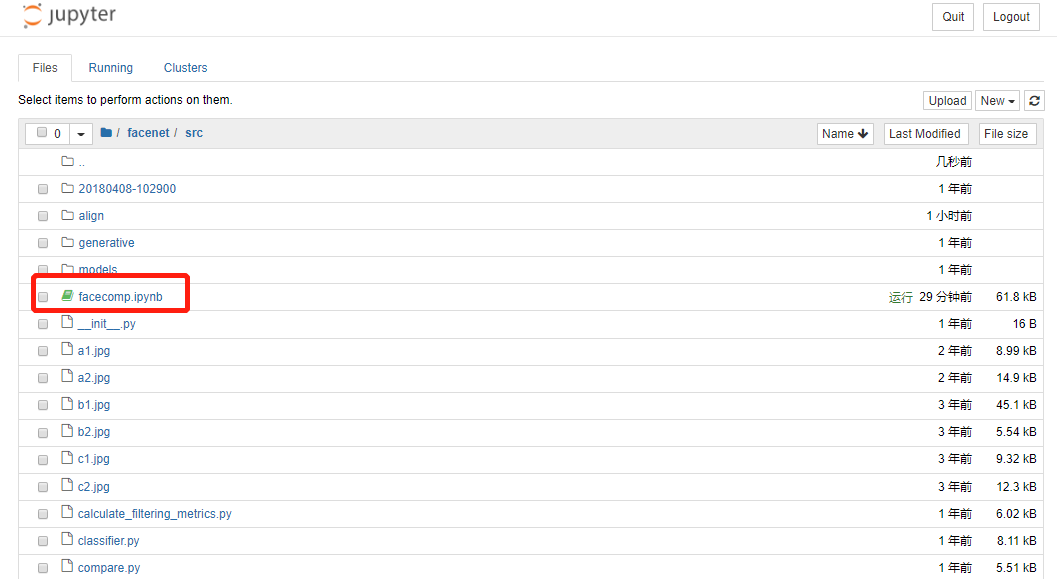
- 在 Jupyer 页面进入
facenet/src,点击facecomp.ipynb:
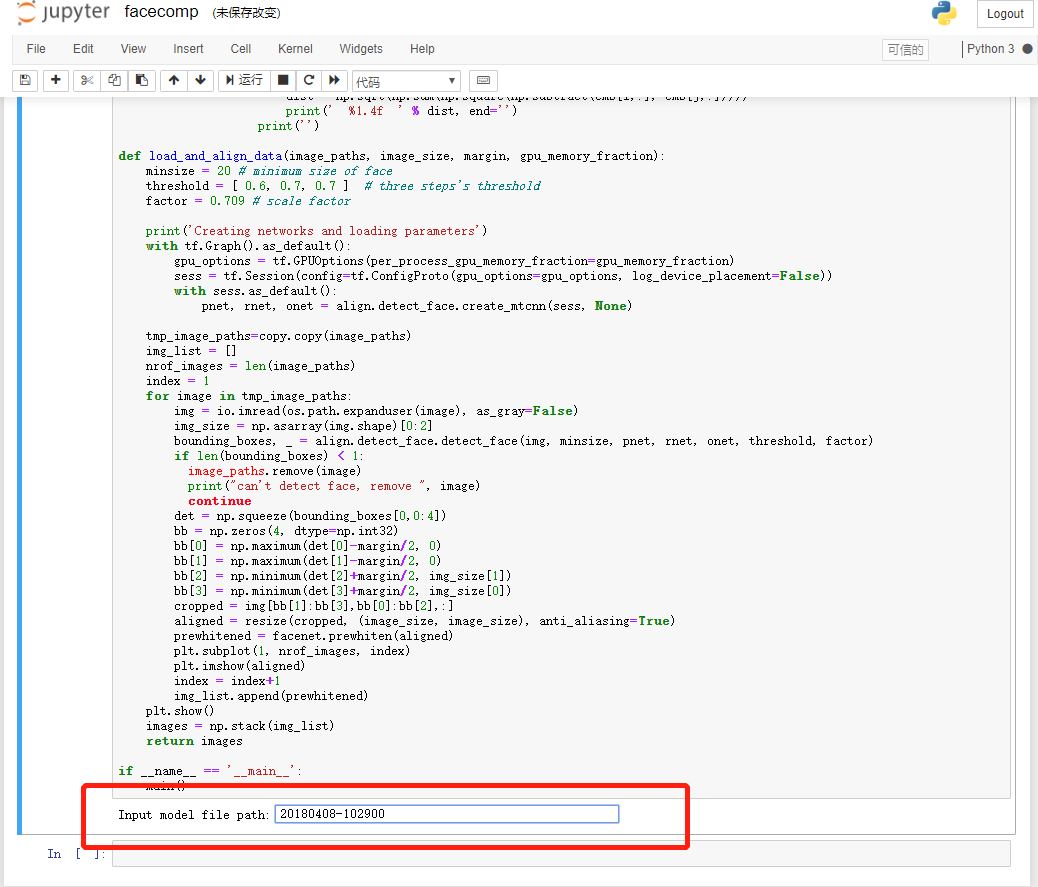
- 打开 facecomp.ipynb 后,鼠标放到代码中,点击运行,在提示输入
model file path时,输入预训练权重路径20180408-102900,按下 Enter 键:
- 提示输入需要计算的照片时,输入
a1.jpg a2.jpg b1.jpg b2.jpg c1.jpg c2.jpg(这里随机选择了 VGGFace2 数据集中 3 个人共 6 张照片作为示例),按下 Enter 键。
将计算并显示 6 张人脸照片相互之间的距离,同一个人的照片,距离较近。如下图所示:

- 训练的过程中,我们可以在宿主机上通过
nvidia-smi工作监视物理 GPU 的使用情况:
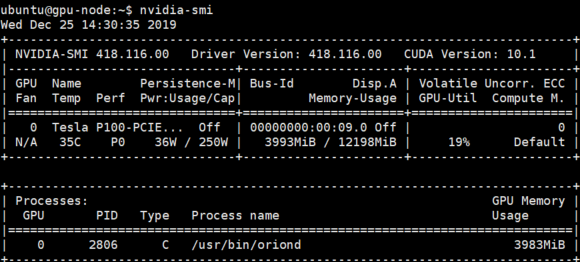
- 结论与上一个训练相同,真正使用物理 GPU 的进程是 Orion Server 的服务进程
/usr/bin/oriond,表明容器中的应用程序使用的是 Orion vGPU 资源。
总结
本文通过 Step-by-step 向大家介绍了 vCPU,以及如何使用 KubeSphere 容器平台 在 Kubernetes 之上安装部署 Orion vGPU,并使用官方 TensorFlow 的两个示例进行模型训练与推理,最终演示了 vGPU 的第一个应用场景 Docker 容器中使用本地节点 GPU 资源。
充分证明了 vGPU 能够兼容已有的 AI 应用和 CUDA 应用,无需修改已有应用程序。并且,借助 Orion vGPU 对 GPU 资源池的管理和优化,提高了整个云和数据中心 GPU 的利用率和吞吐率。
后续我们将推出第二篇文章并结合示例说明 vGPU 的另一个典型应用场景 如何通过 RDMA 使用远程节点 GPU 资源。
参考
目录