






红亚科技
红亚科技成立于 2012 年,是一家聚焦信息技术发展,为教育从业者提供优质教育服务的创新型科技公司,面向国内高校、职业院校提供新一代信息技术专业建设服务,是云计算在职业教育领域落地的实践者。

-
行业
高校信息化、职业教育
-
地点
中国
-
云类型
公有云、混合云、私有云
-
挑战
多集群、异构云环境
-
采用功能
KubeSphere 多集群管理、开发测试环境管理、自定义监控
-
公司简介
红亚科技成立于 2012 年,是一家聚焦信息技术发展,为教育从业者提供优质教育服务的创新型科技公司,面向国内高校、职业院校提供新一代信息技术专业建设服务,是云计算在职业教育领域落地的实践者。

-
背景
青椒课堂是红亚科技推出的理实一体化授课平台,面向信息技术类专业提供教学实训服务。随着项目的迭代,从单体应用演化成为主站 + 资源调度服务(多可用区/客户混合部署)的架构。
在完全使用 KubeSphere 之前,由于我们的副本只在北京有一个集群,所以没有考虑用一个更方便的形式去部署多个集群,当时项目使用可视化 PaaS 平台来进行应用管理,这种形式极大地降低了团队接触上手 Kubernetes 的门槛,使得团队可以快速上手使用容器平台,但随着业务使用的深入,尤其是应用定义、应用配置变更较为繁琐,导致问题频出。
目前项目从开发到生产已经全量使用 Kubernetes ,并使用 KubeSphere 进行管理。项目上线周期在一周一次左右的频率,开发环境进行了自动 CD 触发,每天进行数十次的发布和更新。
-
为什么使用 KubeSphere (QKE)?
选型思路:
对于中小型团队来说,在选择基础设施上,可以尽量使用第三方提供的成熟系统,避免自建。例如 Git 仓库、CI 服务、制品库、部署系统均使用第三方的服务,Kubernetes 也尽量使用厂商提供的托管 K8s,避免采坑;日志、监控报警等系统也是如此(使用 Aliyun sls、Aliyun arms)。个人认为中小型企业在这方面投入过多并没有太大的实际意义,专注于业务即可。
在选择平台的过程中主要有以下几点考虑:
1. 不被某个云服务商所绑定
2. 开源解决方案
3. 可以接受能力范围内的商业化订阅(服务支持付费)
4. 部署难度低
5. 统一认证
6. 操作简便
在集群管理上,原有业务使用阿里云 ACK 进行部署,进行平台迁移时,不希望更换部署环境。另外在管控上,希望网络环境尽量简单,无需打通 VPC 等复杂操作。
-
平台方案:
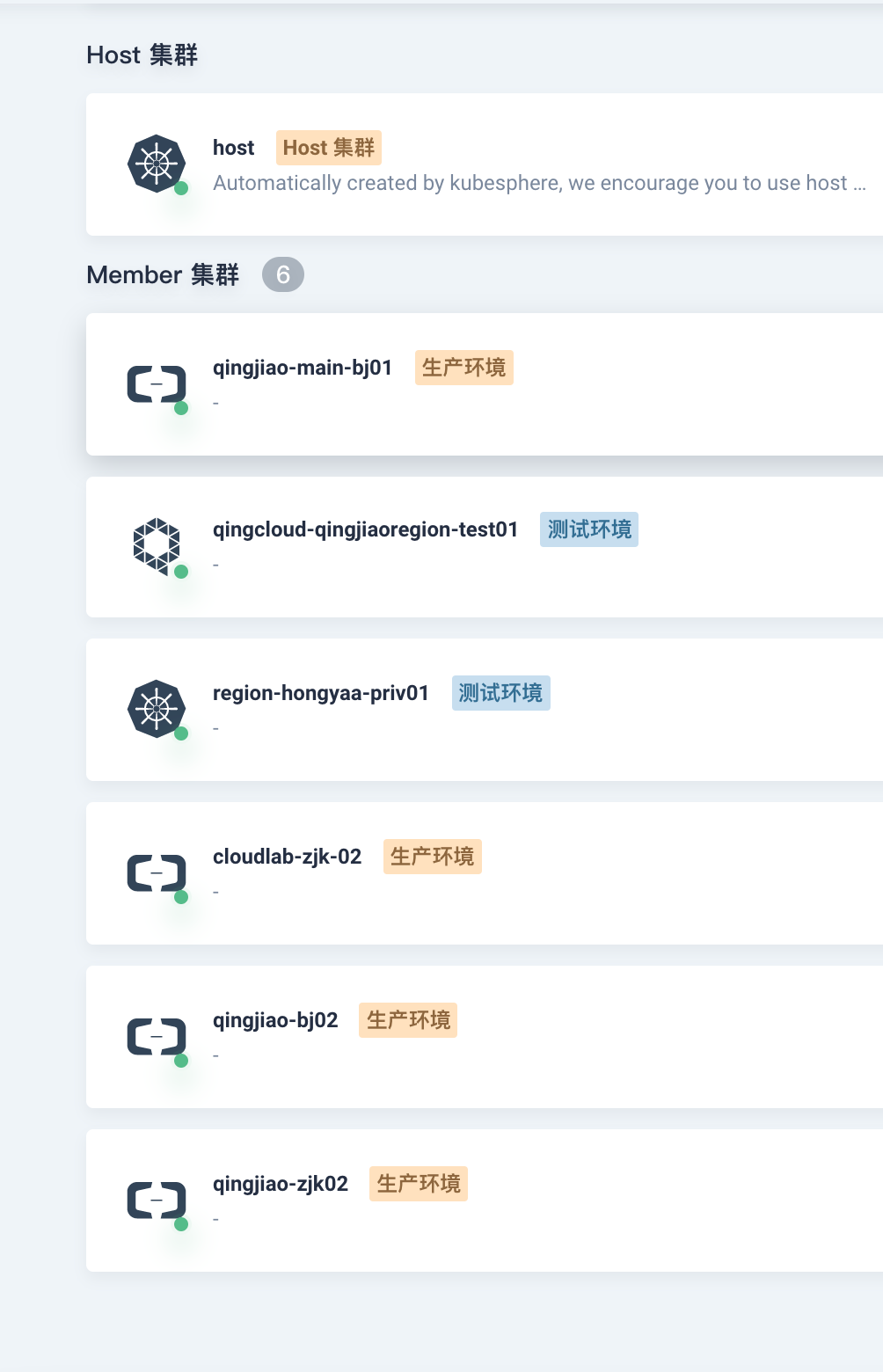
基于以上的选型思路,我们选择 KubeSphere (QKE) 部署在青云QingCloud 公有云,作为多集群的集中控制管理平面 (HOST 集群),开发环境(自建 K8s)、生产环境(Aliyun ACK) 作为 Member 集群。目前将整个开发、生产集群纳入到 KubeSphere 进行管理。
-
-
开源可扩展
-
社区活跃
-
功能设计与业务需求贴合紧密
-
-
基于 KubeSphere 部署应用尝试:青椒课堂 - Region 服务
应用现状及特点:
在确定平台选型后,我们开始把业务的部分服务进行迁移,最初应用使用可视化 PaaS 平台进行多集群部署,在应用变更时,需要在多个集群中进行重复地操作,操作繁琐并且容易出错。
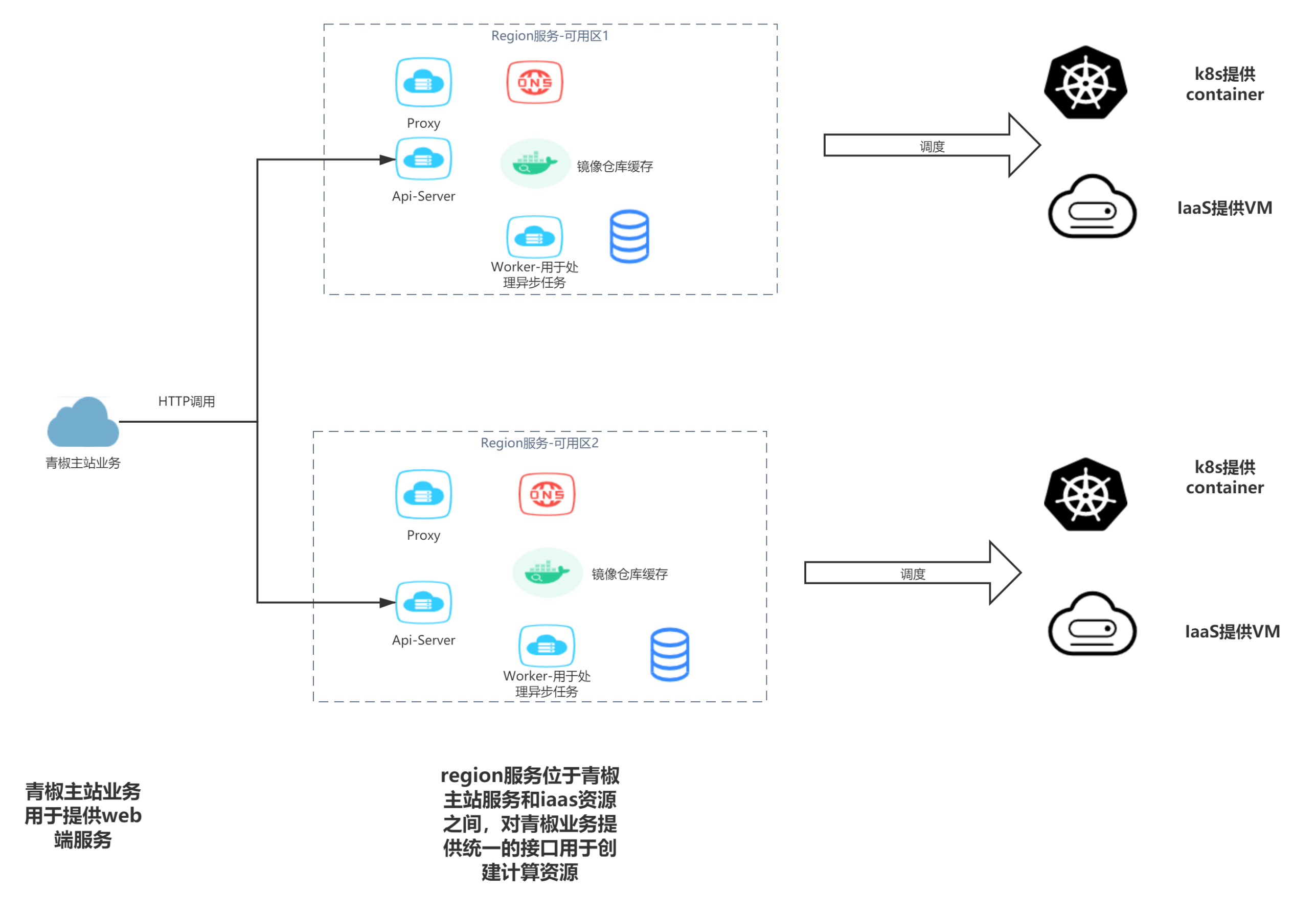
青椒课堂 - Region 服务应用特点如下:
1. 把服务部署在多个地域,比如北京、广东、上海。
2. 各个副本之间不需要进行通讯,只是简单的一个多副本。
3. 直接受主业务的调度,就是提供一个 API server 被主业务去调度。
4. 当业务需要变更的时候,比如增删组件或者组件配置的变更,我们需要在多个副本里面同时进行。用可视化的 PaaS 平台就会有一个问题,我们必须人工调整各个地域。当只有几个时,人工调整还可实现,但随着集群数量的增加,手工调整就过于麻烦。并且人工操作也会有很大概率出现问题,例如组件变更在不同的可用区内没有做到同步调整,导致业务出现故障。
-
如何构建原生 K8s 应用:
团队在最初接触 Kubernetes 时,使用可视化 PaaS 平台操作,这虽然极大地降低了团队上手使用 Kubernetes 的门槛,但同时也造成团队成员不了解资源在 Kubernetes 上的形式,迁移应用时,就必须将应用编写为 K8s 的资源文件,最初编写 yaml 文件会无从下手。此时借助 KubeSphere 的控制台,通过向导创建 Deployment、StatefuleSet、Service、Ingress 等资源,编排完成后,切换至编辑模式即可得到一个完成的 yaml 文件。
-
应用定义管理选型——使用 Helm 的原因:
Helm 作为 Kubernetes 包管理工具,目前使用较为广泛、通用,且 KubeSphere 应用市场也是基于 Helm Chart 制作应用。相对于将应用编写为静态 yaml 文件存储在 Git 仓库中,使用 Helm 作为应用定义的工具便于应用部署多个副本、进行差异化配置。
-
确定部署工具:
最初吸引我们开始使用 KubeSphere 的功能点之一,就是 KubeSphere 的多集群应用功能,因此在部署选型调研时,首先进行了 KubeSphere 的多集群应用测试,遗憾的是,KubeSphere 的多集群应用仅支持自制应用,无法适配 Helm 应用,因此部署工具开始了重新调研。
Spinnaker 通过制品绑定,将“应用定义”的版本,和“应用组件”的版本进行分离,符合我们将“应用定义的过程”进行版本化的思路。最终确定使用 Spinnaker 作为我们的 CD 工具。
-
应用初始化自动化改造:
在迁移应用部署方式之前,关于应用的初始化配置,也较为依赖手动操作。例如更新版本前,进行配置和环境变量的修改、进入容器执行初始化脚本、手动添加 HTTPS 证书和域名等等,这种方式也极易造成部署上线过程中的事故。因此在此次迁移过程中,我们也对应用进行了自动初始化的改造,主要涉及以下几点:
DNS 解析自动化——通过自己开发的工具,读取对应的 Ingress、LoadBlancer 信息进行 DNS 记录的自动配置。
数据库 migration、应用初始化脚本流程化——将数据库 migration 和 应用初始化脚本抽象为 Job 类型的资源,作为部署中的流程执行。
-
自定义监控:
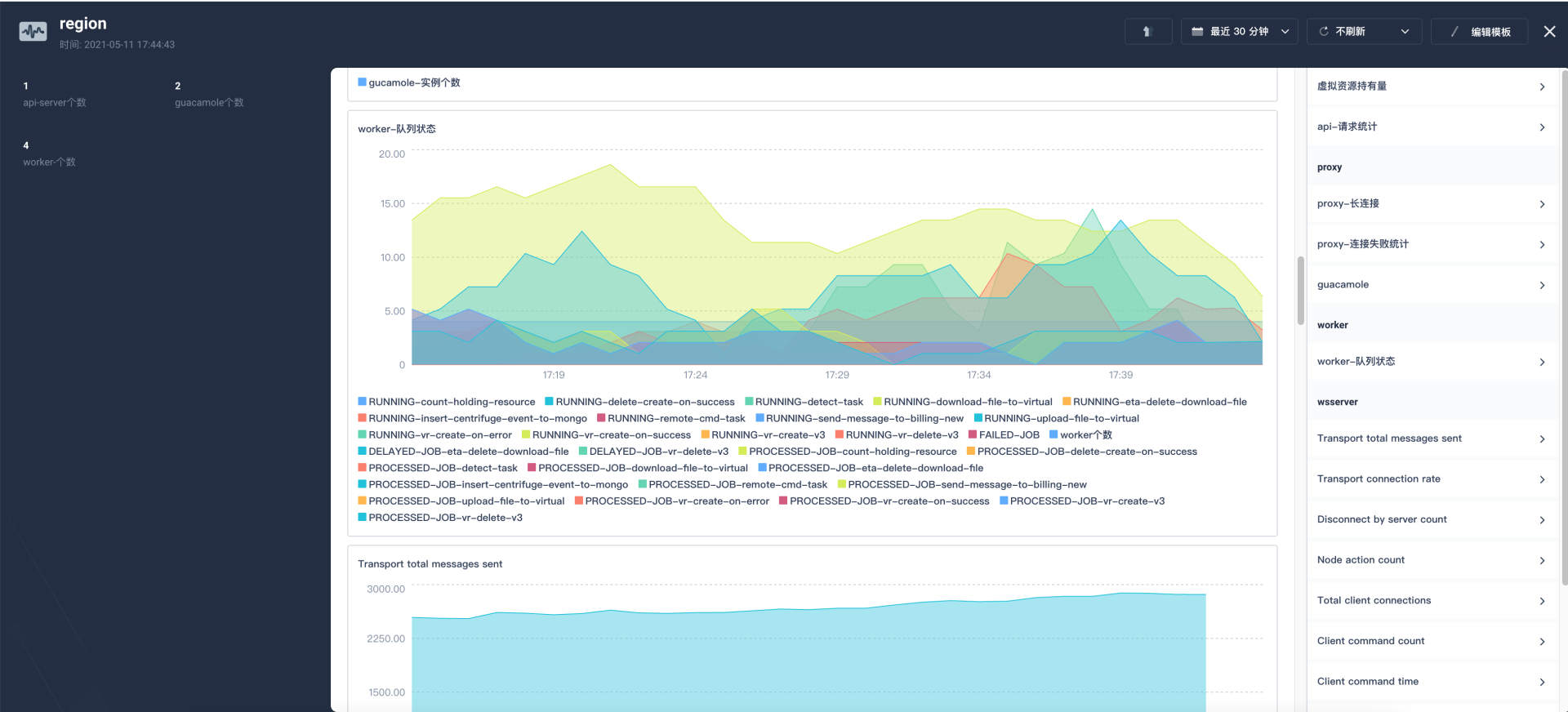
KubeSphere 的自定义监控功能也是最初吸引我们使用的一个重要功能点。在此之前,应用的监控面板存放在阿里云,开发人员需要在多处进行维护和查看,比较繁琐,使用 KubeSphere 自定义监控后即可在同一处管理平面进行服务的维护和监控指标的查看。
KubeSphere Member 集群安装后,默认安装了 prom-operator 组件,应用只需要创建 ServiceMonitor 即可添加监控项,在我们的业务中,也将 ServiceMonitor 的定义放入了 Helm 包中。监控图表的编辑事实上与 Grafana 的语法、操作基本一致,没有额外的学习成本。
不过当前监控面板的编排较为依赖 KubeSphere 控制台,需要在控制台编排好之后获取到 yaml 文件,提交至应用 Helm 内进行多集群分发。
-
统一认证:如何基于 KubeSphere 开发 OAuth 插件
由于公司规模不大,目前公司内部并没有域,也没有 LDAP 服务,之前自主开发的一些内部系统,都使用钉钉作为统一认证。
但钉钉并不能支持标准的 OAuth 协议对接应用,在 KubeSphere 认证时,我们引入了阿里云 IDaaS 产品,将钉钉作为认证源,IDaaS 作为 OAuth Provider, 实现账号的统一认证。
回馈社区——参与社区开发贡献了 KubeSphere IDaaS 插件,PR——support aliyun idaas oauth login。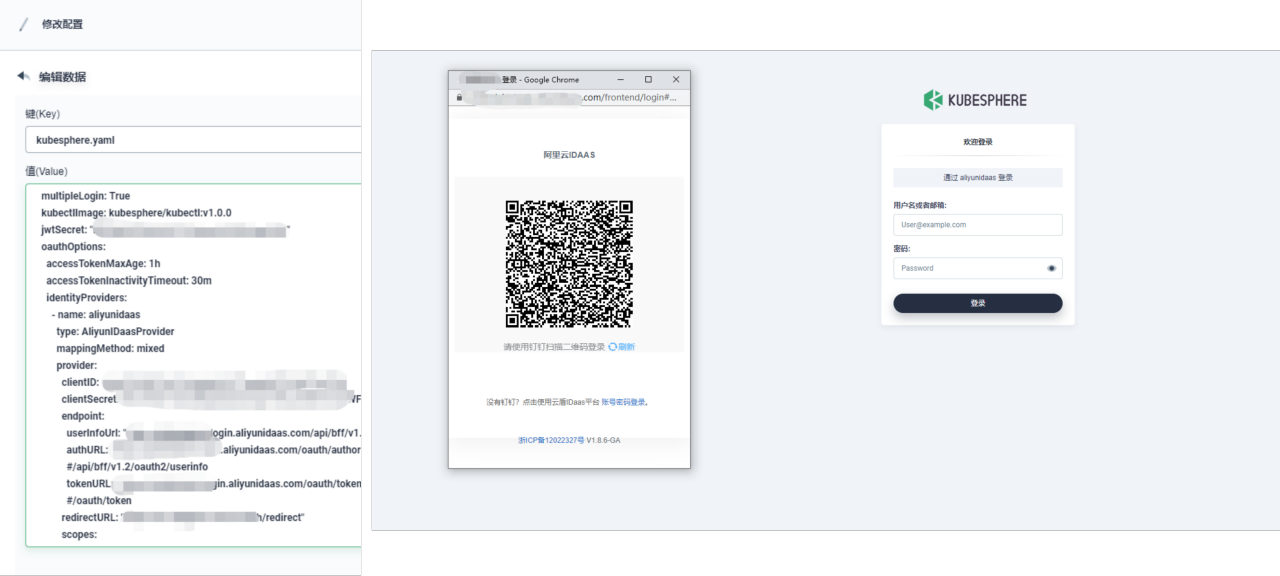
-
开发、生产环境全量迁移至 KubeSphere
经过青椒课堂 - Region 服务的成功迁移和稳定运行后,一段时间内我们面临了 Region 服务的开发测试环境与生产环境不统一的问题,同时主业务也同样存在 Region 服务迁移前的种种问题,于是我们决定将整个开发、测试、生产环境全部迁移至 KubeSphere。
-
快速构建开发测试环境:
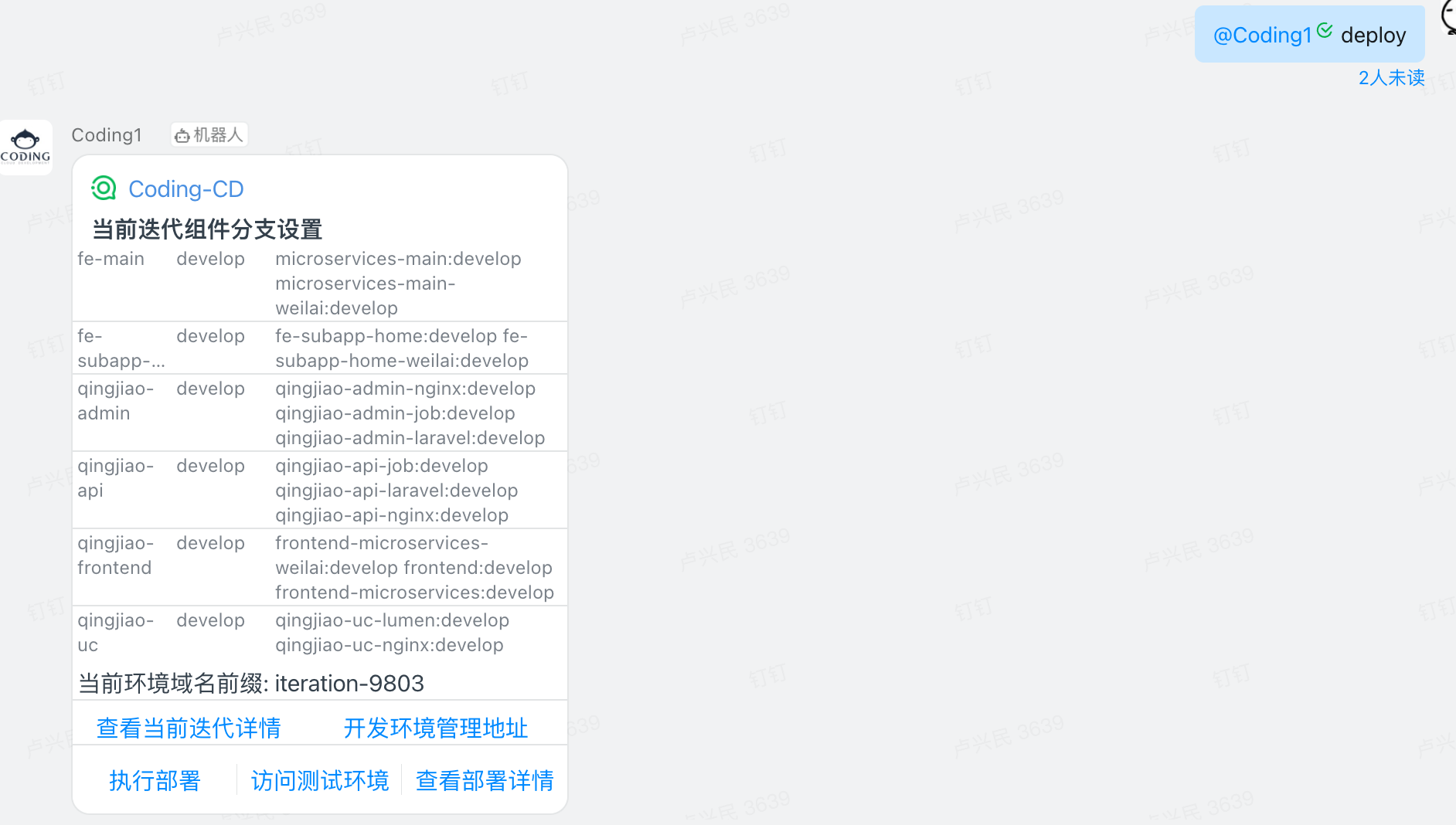
在迁移主业务开发时,也按照 Region 服务的步骤,首先进行了应用 Helm 包的定义。在环境上,通过与协同工具进行对接,以“迭代”为粒度创建开发环境,将 namespace 和域名前缀做为 CD 的启动参数进行动态传入,可以实现快速创建开发测试环境。
通过对接钉钉机器人 outgoing、CD webhook 实现了简单的 chatops。

-

-
-
-
生产环境迁移过程:
由于主业务存在管理后台、异步队列、定时任务等组件,如果直接进行全量迁移,会造成任务 Job 丢失、定时任务重复执行等问题。因此在业务迁移中采取了以下的步骤:
1. 梳理业务中的 DB 等信息
2. 将异步队列使用新老环境共存的方式部署
3. 将定时任务迁移至新模式
4. 迁移整个管理后台
5. web、api 部分进行新老模式共存方式部署、停止旧模式中所有的异步队里处理组件
6. 修改解析,将流量全部迁移至新环境
7. 待 DNS 解析全量生效后(大于 48 小时),将旧环境服务全部下线
在此过程中,得益于 MySQL、Redis、Mongo 等数据库类的组件并未进行自建,全部使用云厂商的组件,存储部分均为对象存储,这使得整个迁移过程较为容易。
-
弹性扩容:KEDA
原生弹性扩容的局限:
1. 基于资源使用,无法快速感知业务负载变化
2. 基于 CPU / 内存进行扩容无法精准控制
-
KEDA 可以解决的问题:
1. 支持 K8s 原有的 cronhpa/ 基于 CPU & 内存的 HPA
2. 基于 Prom 指标进行 HPA,更快反应业务变化
3. 基于 Redis list 长度进行 HPA,适合队列业务场景
4. 基于 MySQL 查询进行 HPA,必要的时候业务可以主动驱动 HPA 进行伸缩
针对我们的业务场景,通过使用 Prom 指标进行 HPA,可以快速根据业务变化进行扩缩容。通过基于 MySQL 查询的 HPA,可以在业务内有大规模的课堂时,进行提前自动化扩容,避免业务峰值到来再进行扩容引起的短时间不可用。
-
KubeSphere和云原生技术的落地让我们这样的小团队在少量的投入下就能获得多种能力,受益匪浅。
红亚科技

-
未来展望
1. ChatOps深入实践
当前通过钉钉、CD、KubeSphere 的打通实现了快速的开发环境创建、更新,开发人员无需在控制台进行操作即可得到独立的测试环境并可以切换组件版本。后续将通过增强 ChatOps 功能,例如对接自动化回归测试,让开发测试流程更加高效。
-
2. 应用发布管理
在当前的应用发布过程中,各个组件所使用的版本相对松散,每一次部署相对于当前生产环境中的变化,只能依靠人工和文档进行管理,没有可以遵循的规则和流程,也存在较大的风险,后续在应用发布的管理上,需要做一些工作来实现整个流程的管控、记录、追溯。
-
3. 灰度发布
由于当前业务全部使用 Nginx Ingress Controller, 所能提供的灰度发布能力较为有限(针对同一个规则仅支持一条灰度),无法满足业务对于多版本灰度的需求,后续也需要针对灰度发布做进一步的调研和实践。
