






中通快递
中通快递创建于 2002 年 5 月 8 日,是一家以快递为核心业务,集跨境、快运、商业、云仓、航空、金融、智能、传媒、冷链等生态版块于一体的综合物流服务企业。

-
行业
物流快递
-
地点
中国
-
云类型
私有云
-
挑战
多集群、高可用、微服务迁移、容器虚机网络打通
-
采用功能
HPA、DevOps、灰度发布、监控和告警
-
公司简介
中通快递创建于 2002 年 5 月 8 日,是一家以快递为核心业务,集跨境、快运、商业、云仓、航空、金融、智能、传媒、冷链等生态版块于一体的综合物流服务企业。2016 年 10 月 27 日在美国纽约证券交易所上市,向全世界打开了一扇了解中国快递发展的窗口;2020 年 9 月 29 日在香港实现二次上市,成为首家同时在美国、中国香港两地上市的快递企业。
中通快递旗下的互联网物流科技平台——中通科技,拥有一支千余人规模的研发团队,秉承“互联网+物流”的理念,与公司战略、业务紧密衔接,为中通生态圈业务打造全场景、全链路的数字化工具,为用户提供卓越的科技产品和优质的服务体验。

-
背景
中通物流是国内业务规模较大,第一方阵中发展较快的快递企业。2019 年,中通各类系统产生的数据流以亿计,各类物理机和虚拟机成千上万,在线微服务更是数不胜数。如此庞大的管理,使得中通业务发展不可持续,因此着手云化改造。在改造过程中,中通选择了 KubeSphere 来作为中通容器管理平台 ZKE 的建设方案。
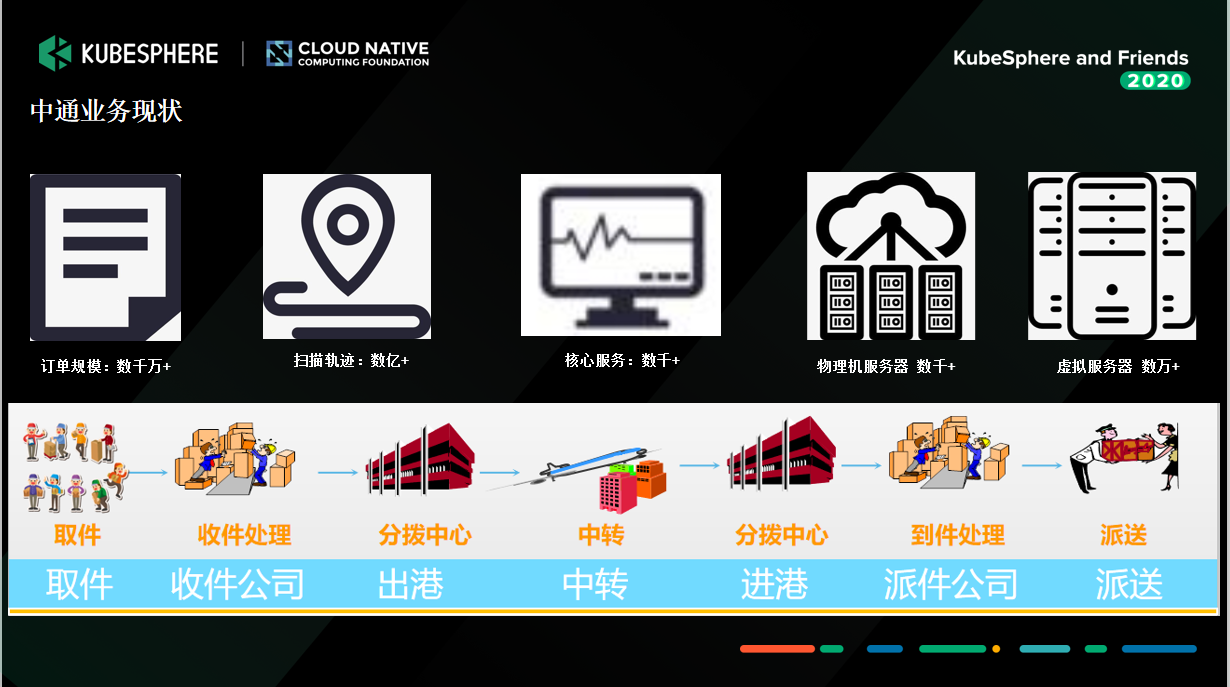
首先介绍下中通的业务现状。
下图是我们 2019 年的数据情况,当我们开始改造时,各类系统产生的数据流以亿计,各类物理机和虚拟机更是成千上万,在线微服务更是数不胜数。截止到 2020 年第三季度,中通快递的市场份额已扩大至 20.8%,基本上是行业领先。这么庞大的管理,随着中通业务的发展基本上是不可持续了,所以我们亟需改造。
-
2019 年我们面临的困难大致有以下五点:
1. 同项目多版本多环境需求:我们项目在迭代时,在同一个项目它已经有 N 多个版本在推进。如果仍以虚机的方式来响应资源,已经跟不上需求了。
2. 项目迭代速度要求快速初始化环境需求:我们的版本迭代速度非常快,快到甚至是一周一迭代。
3. 资源申请麻烦,环境初始化复杂:2019 年时,我们申请资源的方式还比较传统,走工单,搞环境初始化的交付。所以测试人员在测试时非常痛苦,要先申请资源,测试完后还要释放。
4. 现有虚机资源利用率低,僵尸机多:有的资源随着人员的变动或者岗位的变动,变成了僵尸机,数量非常多,尤其是在开发测试环境。
5. 横向扩展差:我们在 “618” 或者 “双 11” 的时候,资源是非常稀缺的,特别是关键核心的服务,之前的做法是提前准备好资源,“618” 或者 “双 11” 结束之后,我们再把资源回收。这其实是一个非常落后的方式。
-
如何进行云化改造?
通过调查,我们认为云化改造可以分为三步:云机房、云就绪和云原生。
当时我们的微服务做的比较靠前,用了 Dubbo 框架,微服务改造已经完成,但方式非常传统,是通过虚机的方式发动。而 Salt 在大量并发的时候有很多问题。所以通过评估,我们亟需对 IaaS 和容器进行改造。
因为我们介入的时候,中通整个业务的开发已经非常多、非常庞大了。我们有一个非常成熟的 DevOps 团队,把发布的 CI/CD 的需求做得非常完善。所以我们介入的话只能做 IaaS 和 Kubernetes 的建设。

-
为何选择 KubeSphere?
在选型的时候,我们首先接触的就是 KubeSphere。当时我通过检索发现了 KubeSphere,然后进行试用,发现界面和体验等方面都非常棒。试用一周之后,我们就决定,使用 KubeSphere 作为中通容器管理平台 ZKE 的建设方案。我印象中我们当时从 KubeSphere 2.0 版本就开始采用了。同时,在 KubeSphere 的影响之下,我们很快就跟青云达成合作协议,直接使用青云的私有云产品来建设中通物流的 IaaS,而 KubeSphere 作为上层的容器 PaaS 平台承载微服务运行。
-
-
降低学习成本
-
产品体验优
-
部署运维简单
-
-
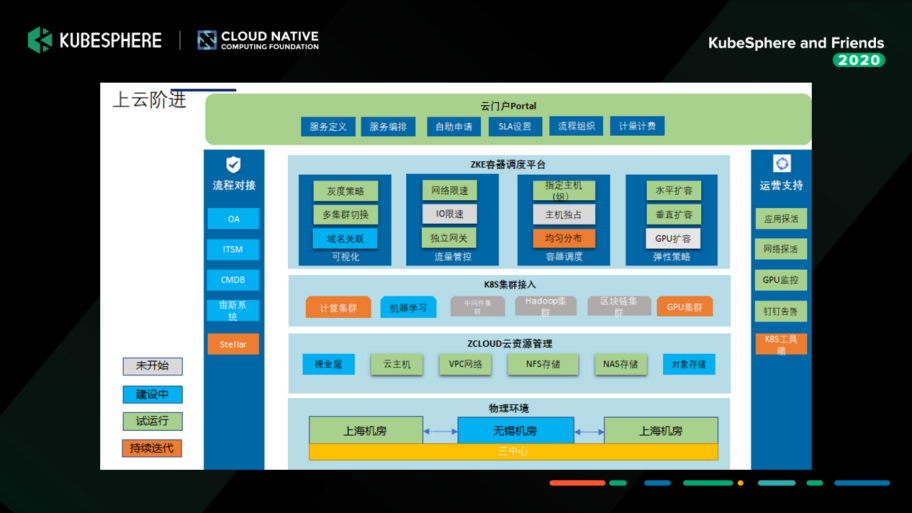
建设方向
基于当时的现状,我们梳理了整个建设的方向。如下图所示,我们会以容器管理平台 KubeSphere 为基础来运行无状态服务,以及可视化管理 Kubernetes 和基础设施资源。而 IaaS 这一块会提供一些有状态的服务,比如中间件。
-
下面这张图相信大家非常熟悉。前面三部分我们应用的效果都非常棒,暂时不作过多介绍,我还是着重讲一下微服务这部分。我们当时试用了 Istio,发现比较重,而且改造的代价比较大。因为我们的微服务本身做的就比较靠前了,所以这块我们暂时没有应用,后续可能会在 Java 的项目上尝试一下。

-
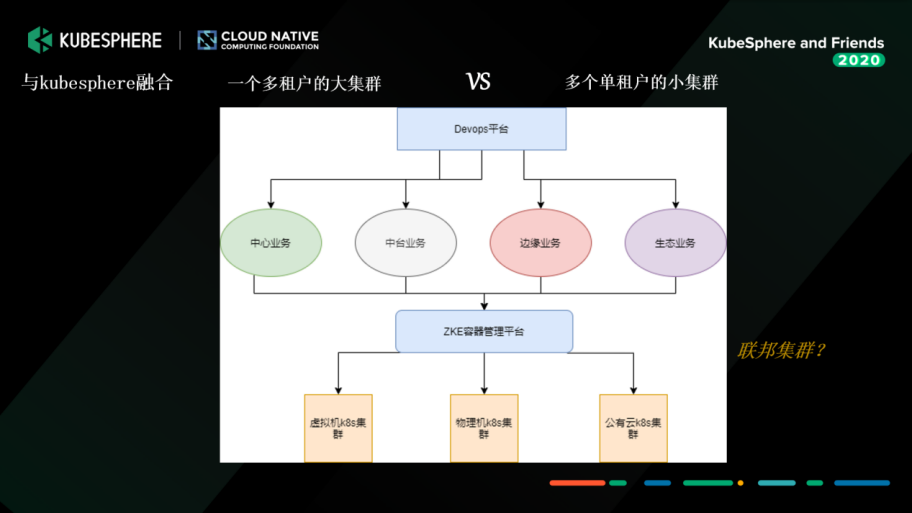
多租户大集群 or 单租户小集群?
选型完成后,我们开始建设。面临的第一个问题就非常棘手:我们到底是建一个多租户大集群,还是建多个单租户的小集群,把它切分开来。
-
与 KubeSphere 团队沟通协作,并充分评估了我们公司的需求之后,决定暂时采取多个小集群的方式,以业务场景(比如中台业务、扫描业务)或者资源应用(比如大数据、边缘的)来进行切分。我们会切成多个小集群,以上面的 DevOps 平台做 CI/CD。KubeSphere 的容器管理平台主要是做一个容器的支撑,在终端就能很好地让用户查看日志、部署、重构等等。
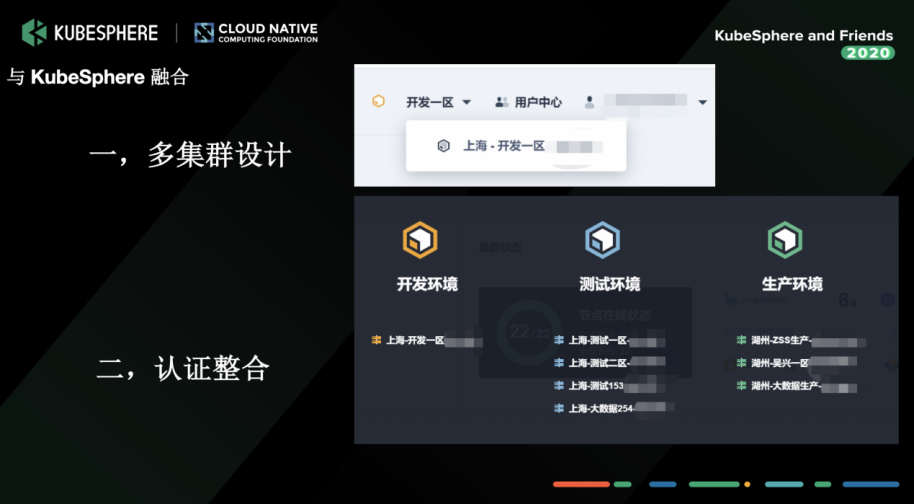
当时我们基于多集群设计,以 KubeSphere v2.0 为蓝图作改造。在开发、测试和生产者三个环境中切,我们在每一个集群里都部署一套 KubeSphere,当然有一些公共的组件我们会拆出来,比如监控、日志这些。
-
我们整合的时候,KubeSphere 团队给了我们非常多的帮助,由于 KubeSphere 2.0 版本只支持 LDAP 对接的方式,而对接 OAuth 的计划放在 3.0 版本里,后来 KubeSphere 团队帮我们整合到 2.0,单独打了一个分支。因为我们公司内部的 OAuth 认证还有自定义的参数,我们开发改造后,通过扫码认证的方式很快就整合进来了。

-
基于 KubeSphere 二次开发实践
下面介绍一下我们在 2019 年夏天到 2020 年 10 月,我们根据自身的业务场景与 KubeSphere 融合所做的定制化开发。
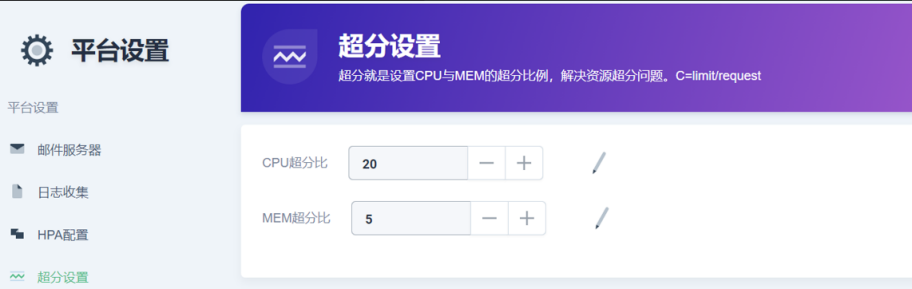
超分设置:
我们通过超分比的方式,只要你设置好 Limit,我们很快就能把你的 Requset 算好,给你整合进来。目前生产的话,CPU是 10,内存大概是 1.5。
-
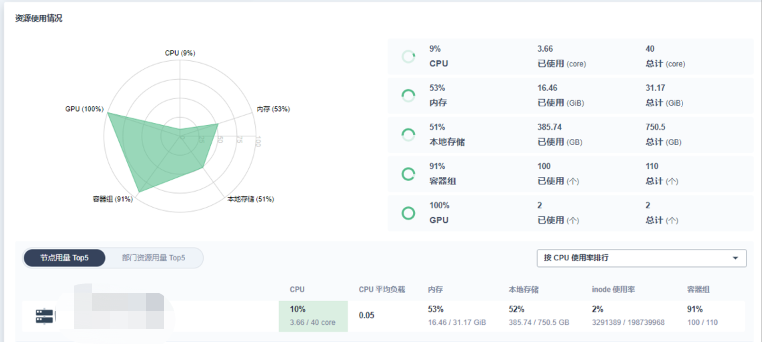
GPU 集群监控:
目前我们的使用还是比较初级,只是把使用情况测出来,做 GPU 集群单独的监控数据的展示。
-
HPA(水平伸缩):
我们使用 KubeSphere,其实对水平伸缩的期望是非常高的。KubeSphere 的资源配置里有水平伸缩,所以我们把水平伸缩这一块单独抽出来设置。水平伸缩的设置配合超分设置,就可以很好地把超分比测出来。很多核心业务已经通过 HPA 的方式,通过 KubeSphere 的界面设置,最终也获得了很好的效果,现在基本不需要运维干预了。特别是有应急场景的需求,比如上游 MQ 消费积压了,需要我们立马扩副本,这样我们可以非常快地响应。

-
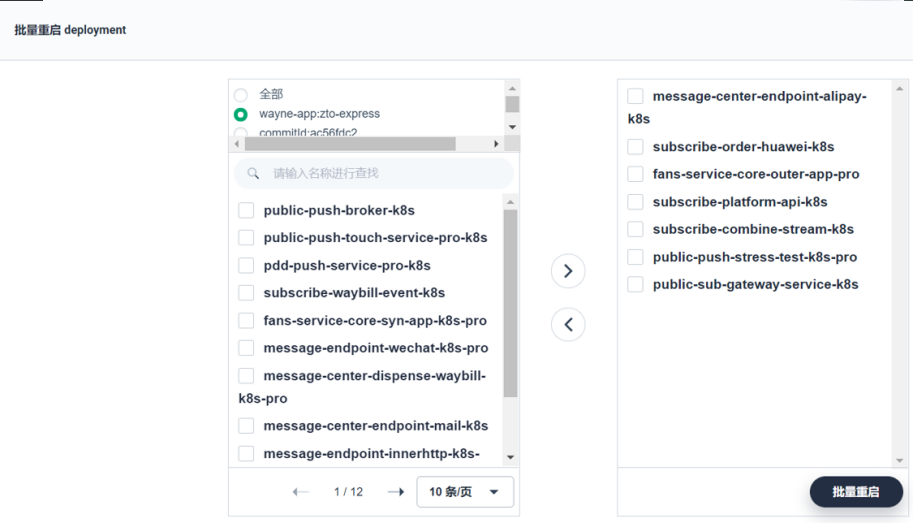
批量重启:
在极端情况下可能要批量重启大量 Deployments,我们单独把这个抽出来做了一个小模块,通过 KubeSphere 平台一键设置,某个项目(NameSpace)下的 Deployment 或者是集群马上可以重启,可以得到很快的响应。
-
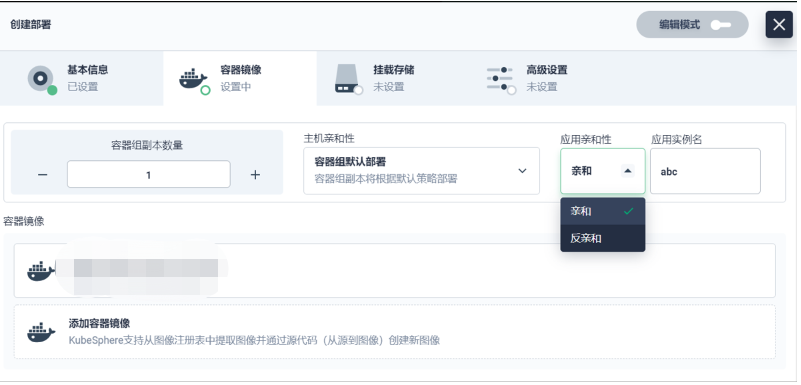
容器亲和性:
在容器亲和性这一块,我们主要做了软性的反亲和。因为我们有些应用它的资源使用可能是相斥的,比如都是 CPU 资源使用型的,我们简单改造了一下,加了一些亲和性的设置。
-
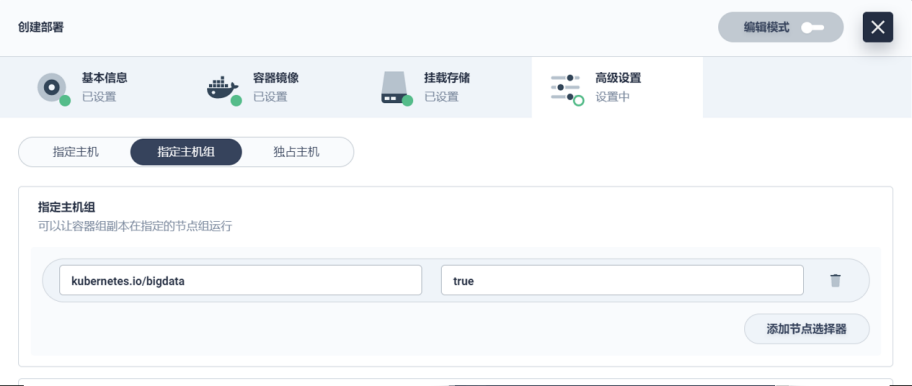
调度策略:
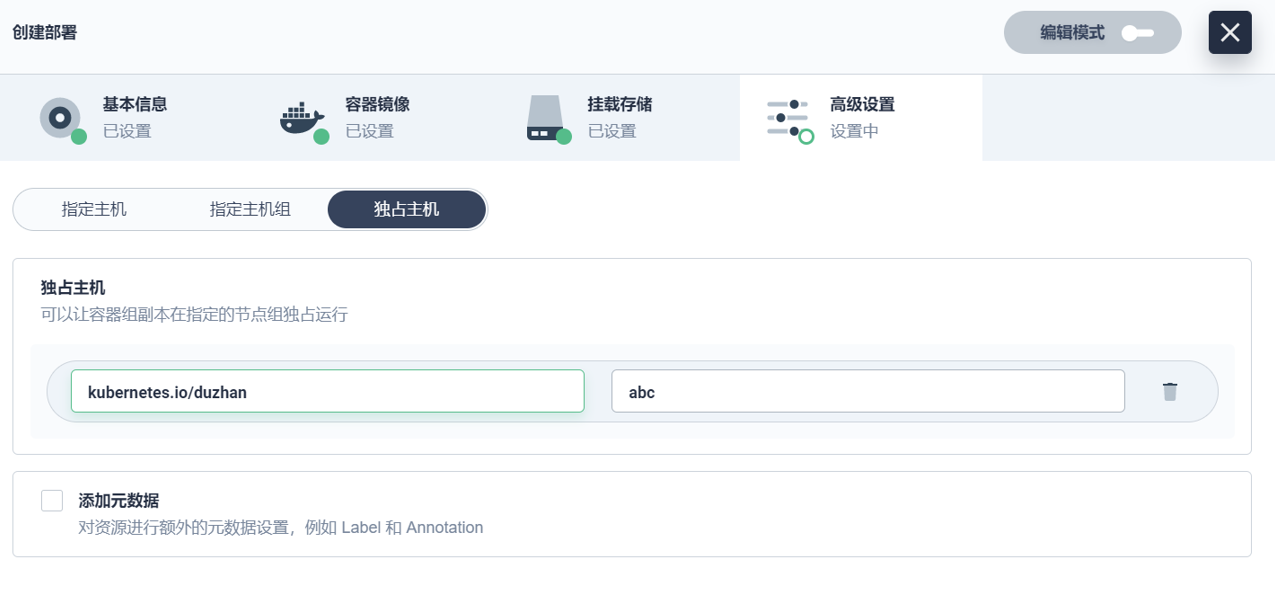
在调度策略方面,因为涉及到比较敏感的后台数据,我们本来打算通过 Yaml 的方式来做。但是后面还是决定通过 KubeSphere 的高级设置页面来实现。我们简单加了一些页面的元素,把指定主机、指定主机组、独占主机的功能,通过表行的形式去配置。我们现在用得特别好的是指定主机组和独占主机这两个功能。
-
简单介绍下独占主机的应用。我们的核心业务在晚上到凌晨六点左右,由于这个时间段服务是比较空闲的,所以用来跑大数据应用非常合适。我们通过独占主机的方式把它空出来,防止它跑满整个集群,所以只是挂了某些点。
-
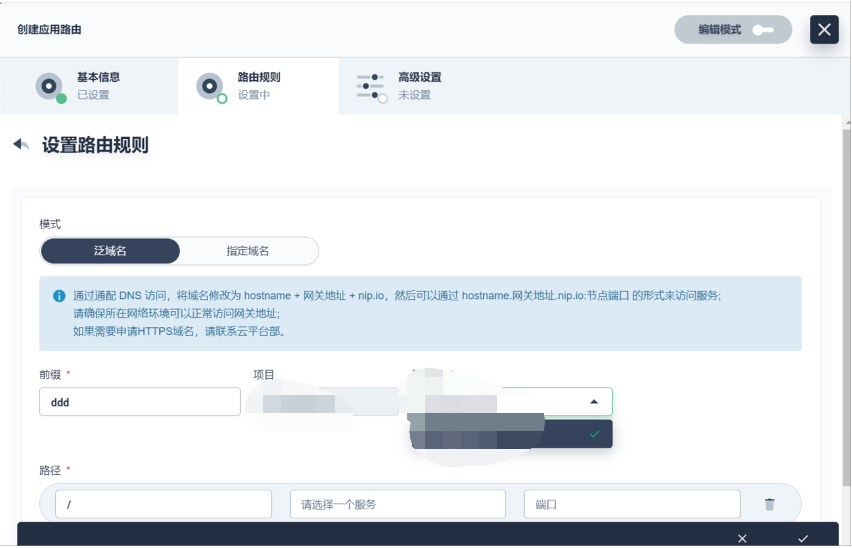
网关:
KubeSphere 是有独立网关的概念的,每一个项目下都有一个单独的网关。独立网关满足了我们的生产需求(因为希望生产走独立网关的方式),但在开发测试有一个泛网关的需求,因为我们希望更快响应服务。所以我们做了一个泛网关,起了一个独立网关,所有开发、测试、域名通过泛域名的方式直接进来。这一块配置好,通过 KubeSphere 界面简单编排一下,基本上我们的服务就直接可以访问。
-
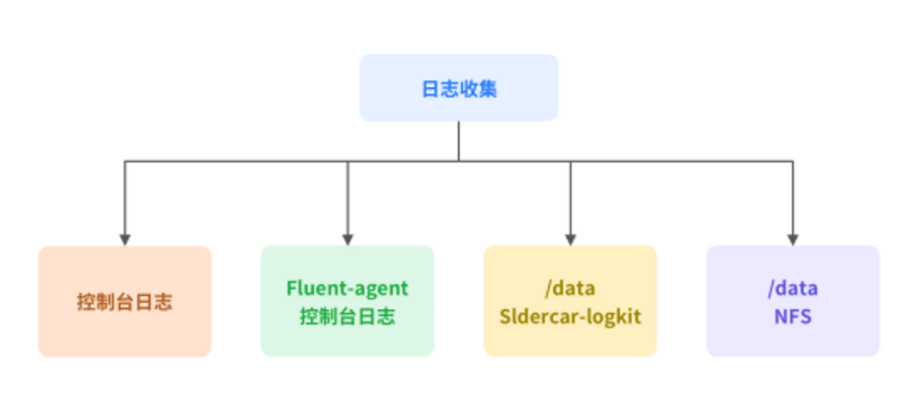
日志收集:
我们一开始是采用官方的方式,也就是通过 Fluent-Bit 的方式收集日志。但后来发现随着业务量上线越来越多,Fluent-Bit 也会经常挂掉。出现这种情况的原因,可能是我们在资源优化方面有缺陷,也可能是整个参数没有调好。所以我们决定启用 Sidecar 的方式来进行日志收集。Java 的服务都会单独起一个 Sidecar,通过 Logkit 这种小的 Agent,把它的日志推到 ElasticSearch 这种中心。在开发测试环境,我们还会用 Fluen-agent 的方式来收集日志。另外有一些生产场景,一定要保证日志的完整性,所以我们会将日志进一步进行磁盘的持久化。通过如下图中所示的四个方式,来收集全部的容器日志。
-
事件跟踪:
我们直接拿了阿里云开源的 Kube-eventer 进行改造。KubeSphere 这一块我们加了事件跟踪可以配置,可以发到我们的钉钉群。尤其在生产上是比较关注业务的变动的,都可以通过定制化配到钉钉群里面。
-
有了 KubeSphere 强大且活跃的社区生态支撑,我们能够轻松将 KubeSphere 整合到公司的产研体系中去。
中通快递

-
未来规划
接下来我们可能批量推生产,我们也提了一些想法,想跟社区交流一下。
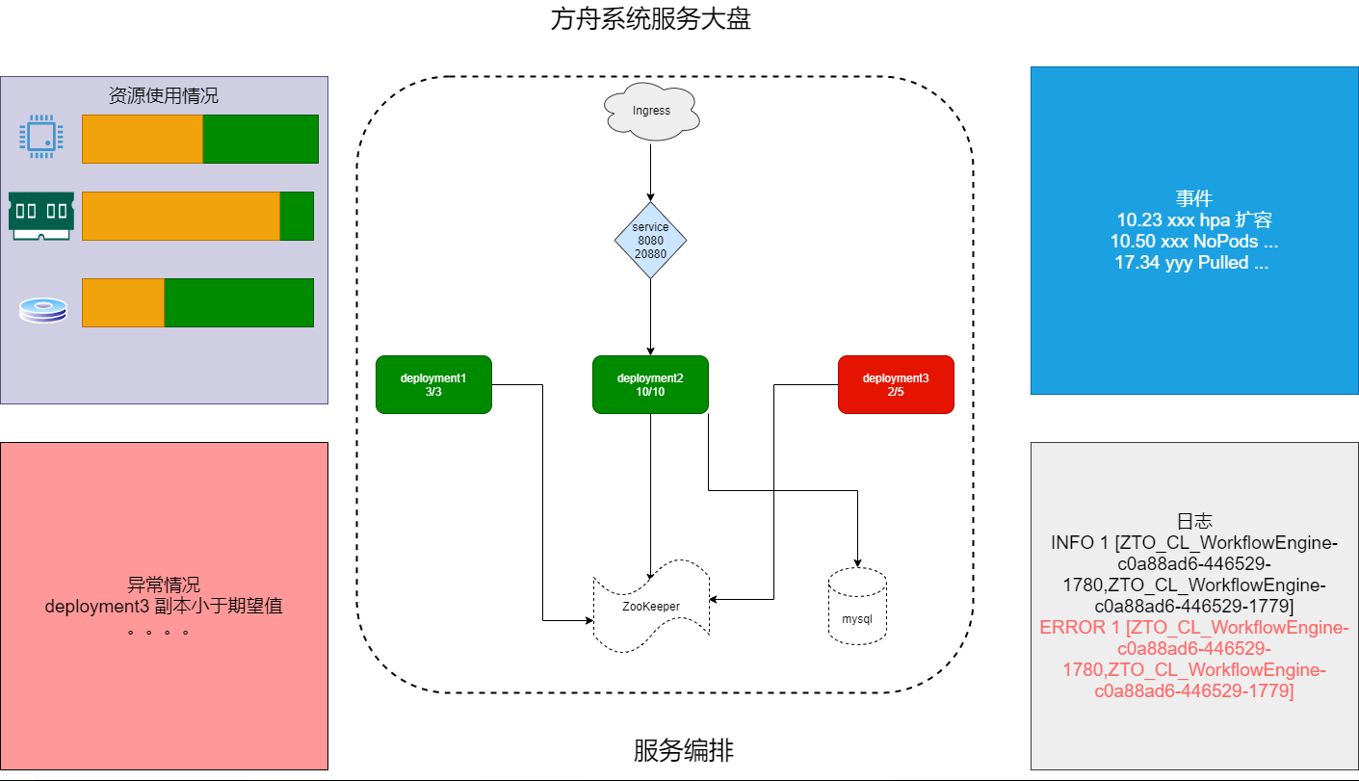
1. 服务大盘
在 KubeSphere 控制台界面是以表行的形式去看我们的微服务等,但我们不知道它们之间的关系,希望通过这种图形化的方式把它展现出来,把它关键的指标——事件、日志、异常情况等直观地呈现出来,以便于我们可视化的运营。目前我们正在规划,明年应该会单独做。
我们想表达的是,无论任何人,包括运维、开发,只要拿到这张图就能知道我们服务的架构是什么样的,目前依赖于哪些中间件、哪些数据库,以及服务目前的状况,比如哪些服务宕了,或者哪些服务目前会有隐藏性的问题。
-
2. 全域 PODS
第二张图我们起的名字叫全域 PODS。在 KubeSphere 官方这边应该叫热力图。我们希望从整个集群的视角上,能够看到目前所有的 PODS 现状,包括它的颜色变化和资源状态。

-
3. 边缘计算
针对边缘计算与容器的结合,我们通过调研,最终选择了 KubeEdge,中通适合边缘计算落地的场景包括:
中转快件扫描数据上传:各个中转中心快件数据扫描后,首先经过各中转中心部署的服务进行第一次处理,然后把处理过的数据上传到数据中心。各个中转中心部署的服务现在是通过自动化脚本远程发布,目前中通所有中转中心将近 100 个,每次发布需要 5 个人/天。如果通过边缘管理方案,可以大幅度减少人力发布和运维成本,另外可以结合 Kubernetes 社区推荐的 Operator 开发模式来灵活定制发布策略。
操作工暴力分拣自动识别:中通为了降低快件破损率,在各中转中心及其网点流水线安置摄像头扫描操作工日常操作,扫描到的数据会传到本地的 GPU 盒子进行图片处理,处理完的数据传到数据中心。当前 GPU 盒子内的应用发布为手动登录发布,效率非常低;盒子经常还会出现失联,发现该问题时可能已经过了很长时间。通过 KubeEdge 边缘方案也可以解决当前发布与节点监控问题。
各中心智慧园区项目落地:该项目也正在公司落地,后续也会有很多边缘场景可以借助容器技术解决当前痛点。
