






发布于:2019-06-24
本文总阅读量:





Porter-面向裸金属环境的 Kubernetes 开源负载均衡器
我们知道,在 Kubernetes 集群中可以使用 “LoadBalancer” 类型的服务将后端工作负载暴露在外部。云厂商通常为 Kubernetes 提供云上的 LB 插件,但这需要将集群部署在特定 IaaS 平台上。然而,许多企业用户通常都将 Kubernetes 集群部署在裸机上,尤其是用于生产环境时。而且对于本地裸机集群,Kubernetes 不提供 LB 实施。Porter 是一个专为裸金属 Kubernetes 集群环境而设计的开源的负载均衡器项目,可完美地解决此类问题。
Kubernetes 服务介绍
在 Kubernetes 集群中,网络是非常基础也非常重要的一部分。对于大规模的节点和容器来说,要保证网络的连通性、网络转发的高效,同时能做的 IP 和 Port 自动化分配和管理,并提供给用户非常直观和简单的方式来访问需要的应用,这是非常复杂且细致的设计。
Kubernetes 本身在这方面下了很大的功夫,它通过 CNI、Service、DNS、Ingress 等一系列概念,解决了服务发现、负载均衡的问题,也大大简化了用户的使用和配置。其中的 Service 是 Kubernetes 微服务的基础,Kubernetes 是通过 kube-proxy 这个组件来实现服务的。kube-proxy 运行在每个节点上,监听 API Server 中服务对象的变化,通过管理 iptables 来实现网络的转发。用户可以创建多种形式的 Service,比如基于 Label Selector 、Headless 或者 ExternalName 的 Service,kube-proxy 会为 Service 创建一个虚拟的 IP(即 Cluster IP),用于集群内部访问服务。
暴露服务的三种方式
如果需要从集群外部访问服务,即将服务暴露给用户使用,Kubernetes Service 本身提供了两种方式,一种是 NodePort,另外一种是 LoadBalancer。另外 Ingress 也是一种常用的暴露服务的方式。
NodePort
如果将服务的类型设置为 NodePort,kube-proxy 就会为这个服务申请一个 30000 以上的端口号(默认情况下),然后在集群所有主机上配置 IPtables 规则,这样用户就能通过集群中的任意节点加上这个分配的端口号访问服务了,如下图
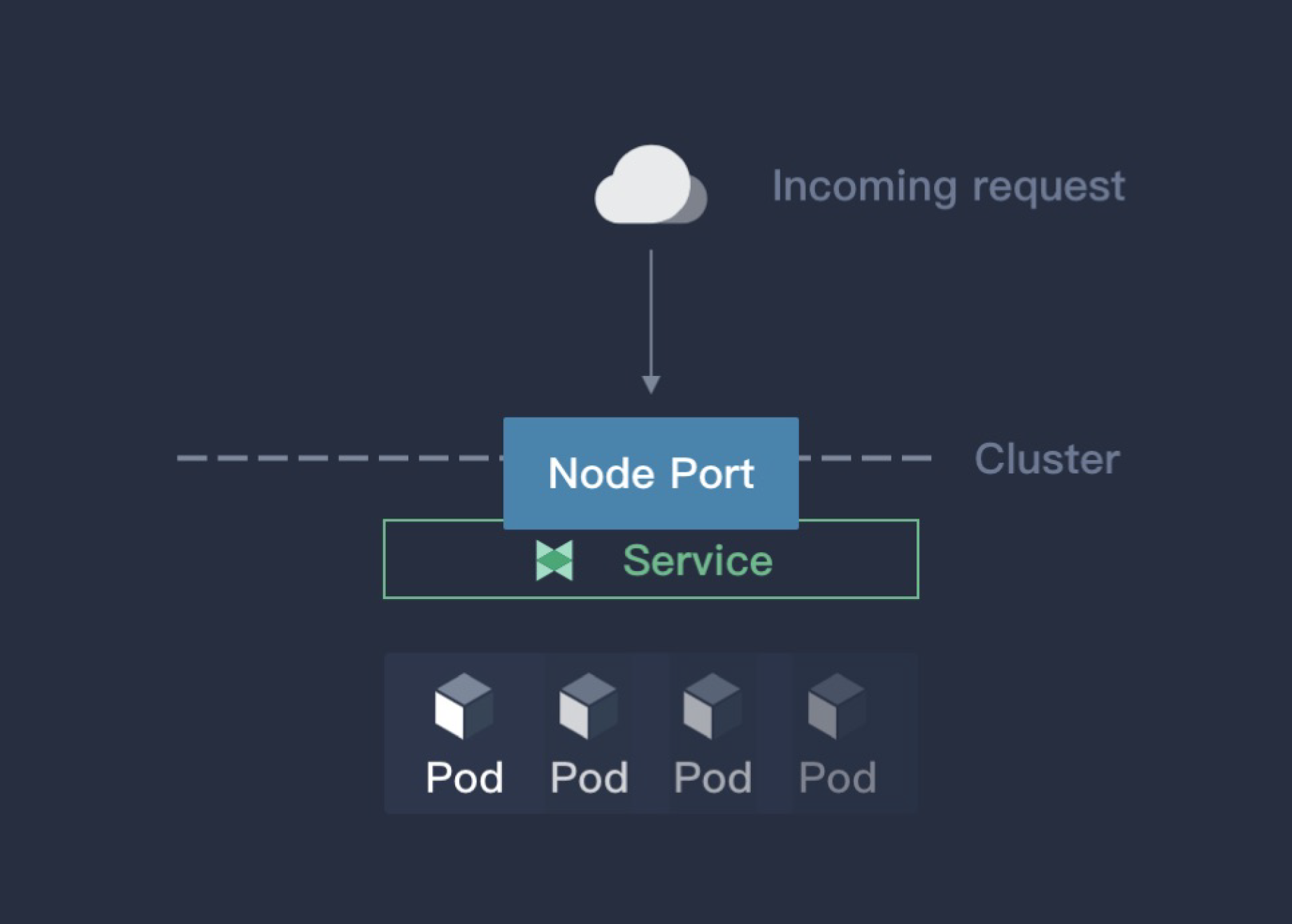
NodePort 是最方便的暴露服务的方式,缺点也很明显:
- 基于 SNAT 进行访问,Pod 无法看到真正的 IP。
- NodePort 是将集群中的一个主机作为跳板访问后端服务,所有的流量都会经过跳板机,很容易造成性能瓶颈和单点故障,难以用于生产环境。
- NodePort 端口号一般都是用大端口,不容易记忆。
NodePort 设计之初就不是用于生产环境暴露服务的方式,所以默认端口都是一些大端口。
LoadBalancer
LoadBalancer 是 Kubernetes 提倡的将服务暴露给外部的一种方式。但是这种方式需要借助于云厂商提供的负载均衡器才能实现,这也要求了 Kubernetes 集群必须在云厂商上部署。LoadBalancer 的原理如下:
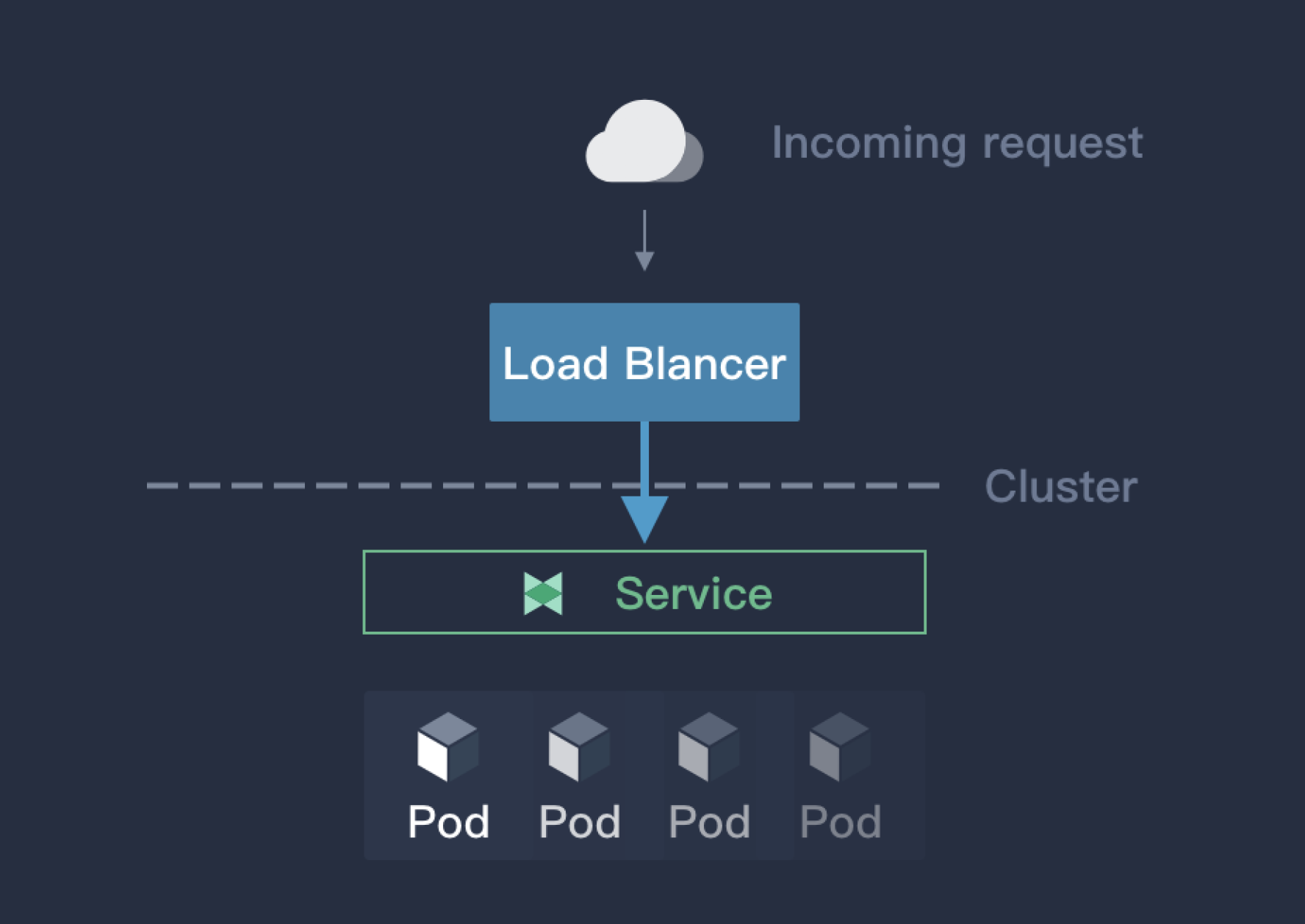
LoadBalancer 通过云厂商的 LB 插件实现,LB 插件基于 Kubernetes.io/cloud-provider 这个包实现,这个包会自动选择合适的后端暴露给 LB 插件,然后 LB 插件由此创建对应的负载均衡器,网络流量在云服务端就会被分流,就能够避免 NodePort 方式的单点故障和性能瓶颈。LoadBalancer 是 Kubernetes 设计的对外暴露服务的推荐方式,但是这种方式仅仅限于云厂商提供的 Kubernetes 服务上,对于物理部署或者非云环境下部署的 Kubernetes 集群,这一机制就存在局限性而无法使用。
Ingress
Ingress 并不是 Kubernetes 服务本身提供的暴露方式,而是借助于软件实现的同时暴露多个服务的一种类似路由器的插件。Ingress 通过域名来区分不同服务,并且通过 annotation 的方式控制服务对外暴露的方式。其原理如下图:
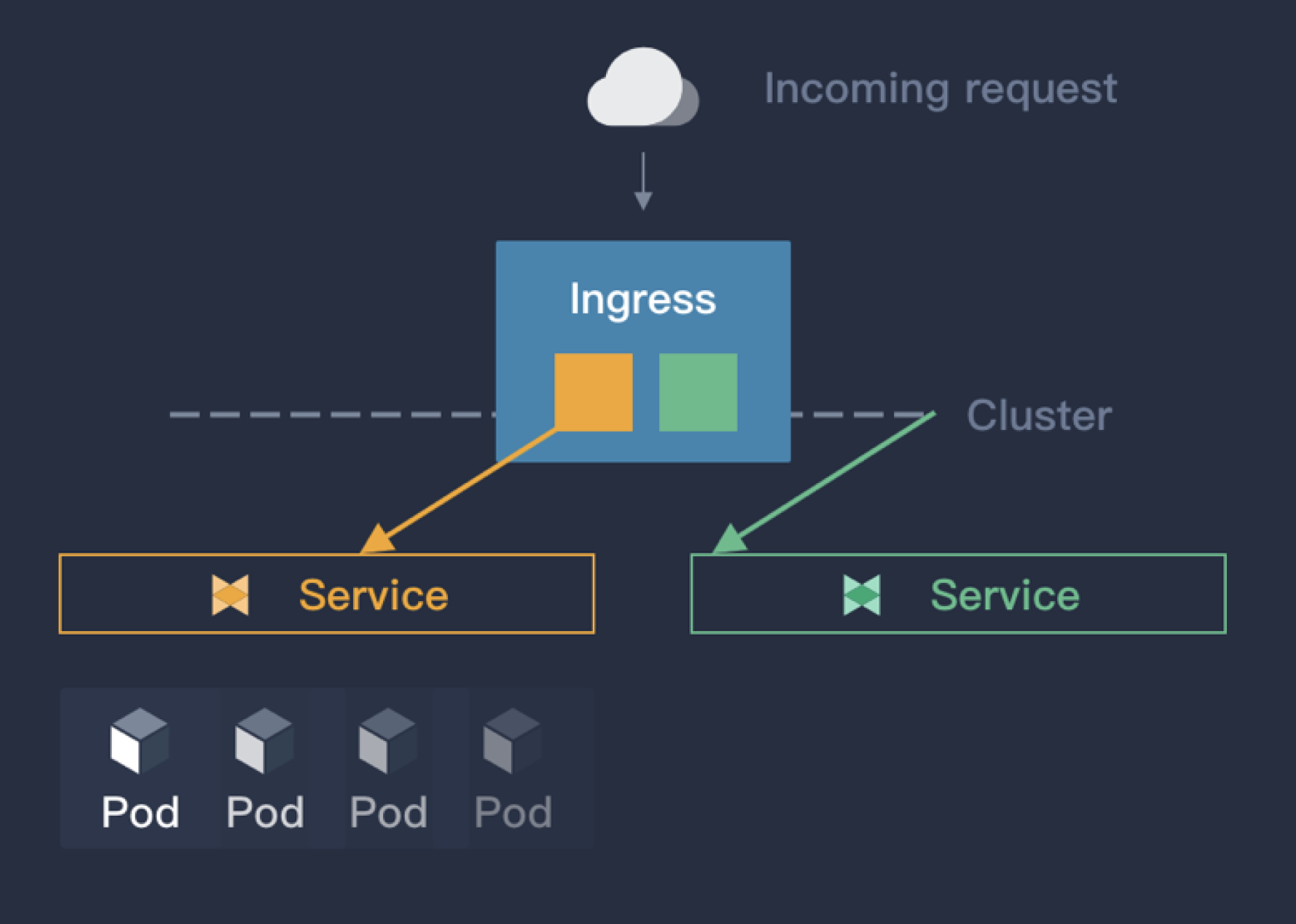
相比于 NodePort 和 LoadBalancer,Ingress 在企业业务场景中应该是使用的最多的,原因有:
- 相比 kube-proxy 的负载均衡,Ingress controller 能够实现更多的功能,诸如流量控制,安全策略等。
- 基于域名区分服务,更加直观。也不需要用到 NodePort 中的大端口号。
但是在实际场景中,Ingress 也需要解决下面的一些问题:
- Ingress 多用于 L7,对于 L4 的支持不多。
- 所有的流量都会经过 Ingress Controller,需要一个 LB 将 Ingress Controller 暴露出去。
第一个问题,Ingress 也可以用于 L4,但是对于 L4 的应用,Ingress 配置过于复杂,最好的实现就是直接用 LB 暴露出去。 第二个问题,测试环境可以用 NodePort 将 Ingress Controller 暴露出去或者直接 hostnetwork,但也不可避免有单点故障和性能瓶颈,也无法很好的使用 Ingress-controller 的 HA 特性。
Porter 介绍
Porter 是 KubeSphere 团队研发的一款开源的基于 BGP 协议的云原生负载均衡器插件。它的主要特性有:
- 基于路由器 ECMP 的负载均衡
- 基于 BGP 路由动态配置
- VIP 管理

Porter 的所有代码和文档已在 GitHub 开源,欢迎大家关注 (Star) 和使用。
如何快速部署使用
Porter 目前已在如下两种环境下进行过部署和测试,并将部署测试与使用步骤的详细文档记录在 GitHub,大家可以通过以下链接查看,建议大家动手部署实践一下。
原理
ECMP
ECMP(Equal-Cost Multi-Pathing,等价路由)即存在多条到达同一个目的地址的相同开销的路径。当设备支持等价路由时,发往该目的 IP 或者目的网段的三层转发流量就可以通过不同的路径分担,实现网络的负载均衡,并在其中某些路径出现故障时,由其它路径代替完成转发处理,实现路由冗余备份功能。如下图:
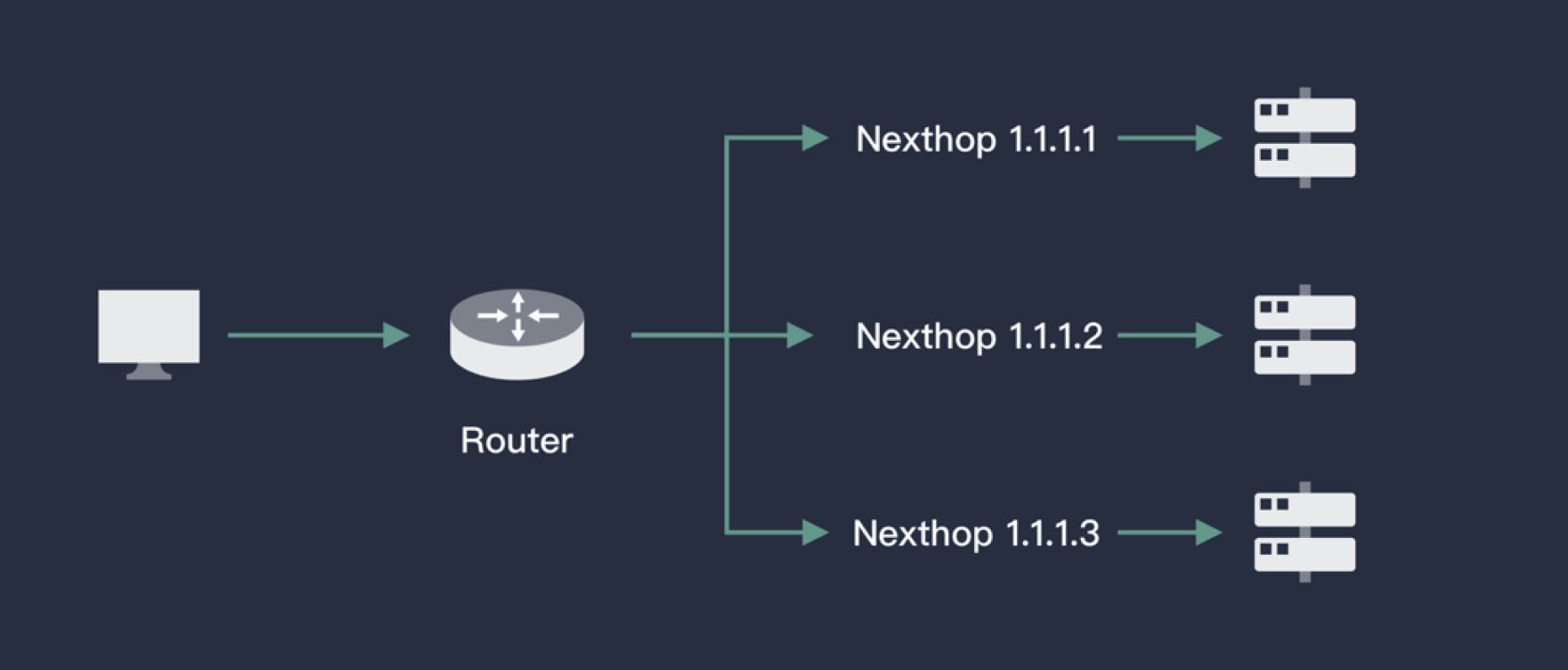
借助于路由器(虚拟路由器),对于某一个IP(对应服务的VIP),ECMP能根据一定的Hash算法从已知的路由中来选择下一跳(Pod),从而实现负载均衡的目的。一般的路由器(虚拟路由器)都具备 ECMP 的能力,Porter 要做的就是查询 Kubernetes API Server,将一个服务对应的后端 Pod 信息通过路由的方式发送给路由器。
BGP
在Kubernetes中,Pod可能会漂移,对于路由器来说,一个服务VIP的下一跳是不固定的,等价路由的信息会经常更新。实际上我们参考 Calico,使用了 BGP(Border Gateway Protocol,边界网关协议)实现路由的广播。BGP 是互联网上一个核心的去中心化自治路由协议,在互联网领域用的比较多。BGP 不同于其他路由协议,BGP使用了L4来保证路由信息的安全更新。同时由于BGP的去中心化特性,很容易搭建一个高可用路由层,保证网络的持续性。
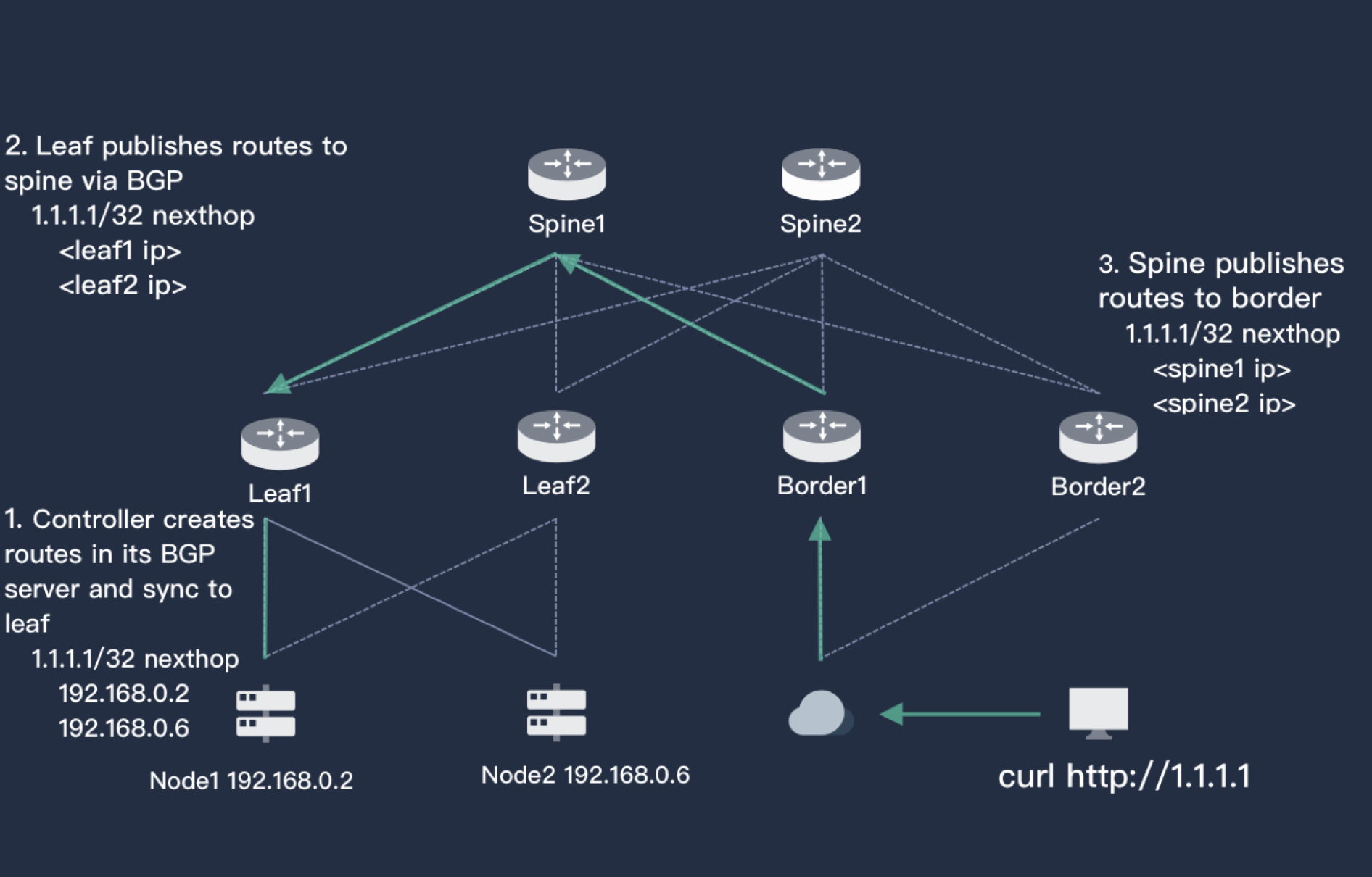
上图简单描述了 Porter 中 BGP 的实现原理。图中左下是一个两节点的 Kubernetes 集群,集群上方是有两个路由器 leaf1 和 leaf2,leaf 连接了核心交换机层 spine,也同样是两个。最右侧是用户,对应的路由器是 border,border 也连接了 spine,用户和 Kubernetes 服务器三层是可达的。 Kubernetes 集群中创建了 Service,并且使用了 Porter,Porter 为其分配了一个 1.1.1.1 的 VIP(或者手工指定),Porter 通过 BGP 告知 leaf1 和 leaf2,访问 1.1.1.1 的下一跳可以是 node1,也可以是 node2。leaf 一层也会将这个信息告知 spine,spine 的 BGP 经过计算得知访问 1.1.1.1 的下一跳是 leaf1,leaf2。按照同样的逻辑,这个路由也会更新到 border,这样用户访问 1.1.1.1 的完整路径就有了。同时,由于这个图中每一层都有HA,所以外界访问 1.1.1.1 的路径就有 2*2*2*2= 16 条,流量能够在整个网络中被分流,并且任意一层一个路由器宕机都不会影响用户的访问。
架构
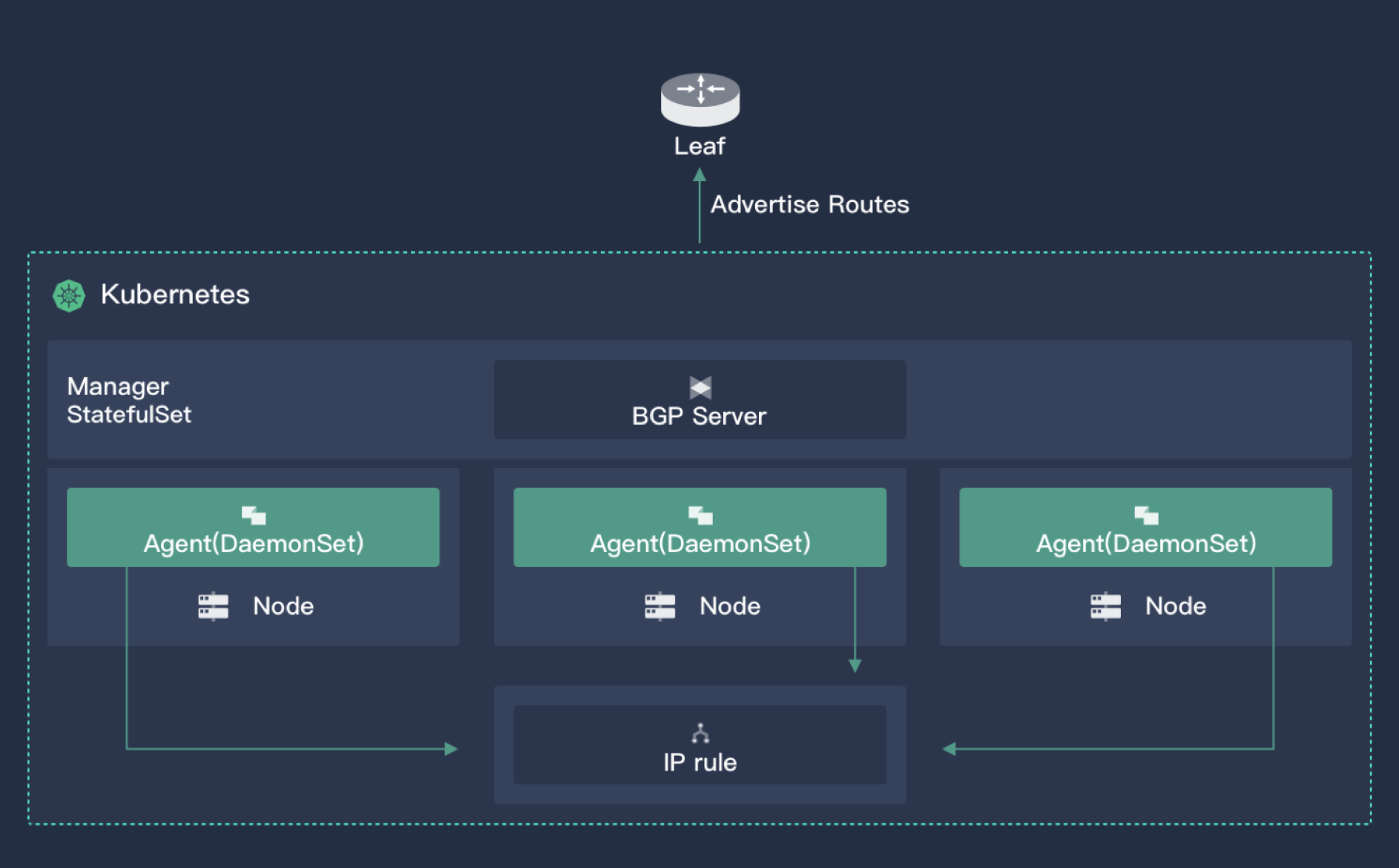
Porter 有两个组件,一个核心控制器和一个部署在所有节点上的 agent。核心控制器主要功能有:
- 监控集群中的 Service 以及对应的 endpoints,获取 Pod漂移信息
- VIP 存储与分配
- 与外界建立 BGP 协议,广播路由
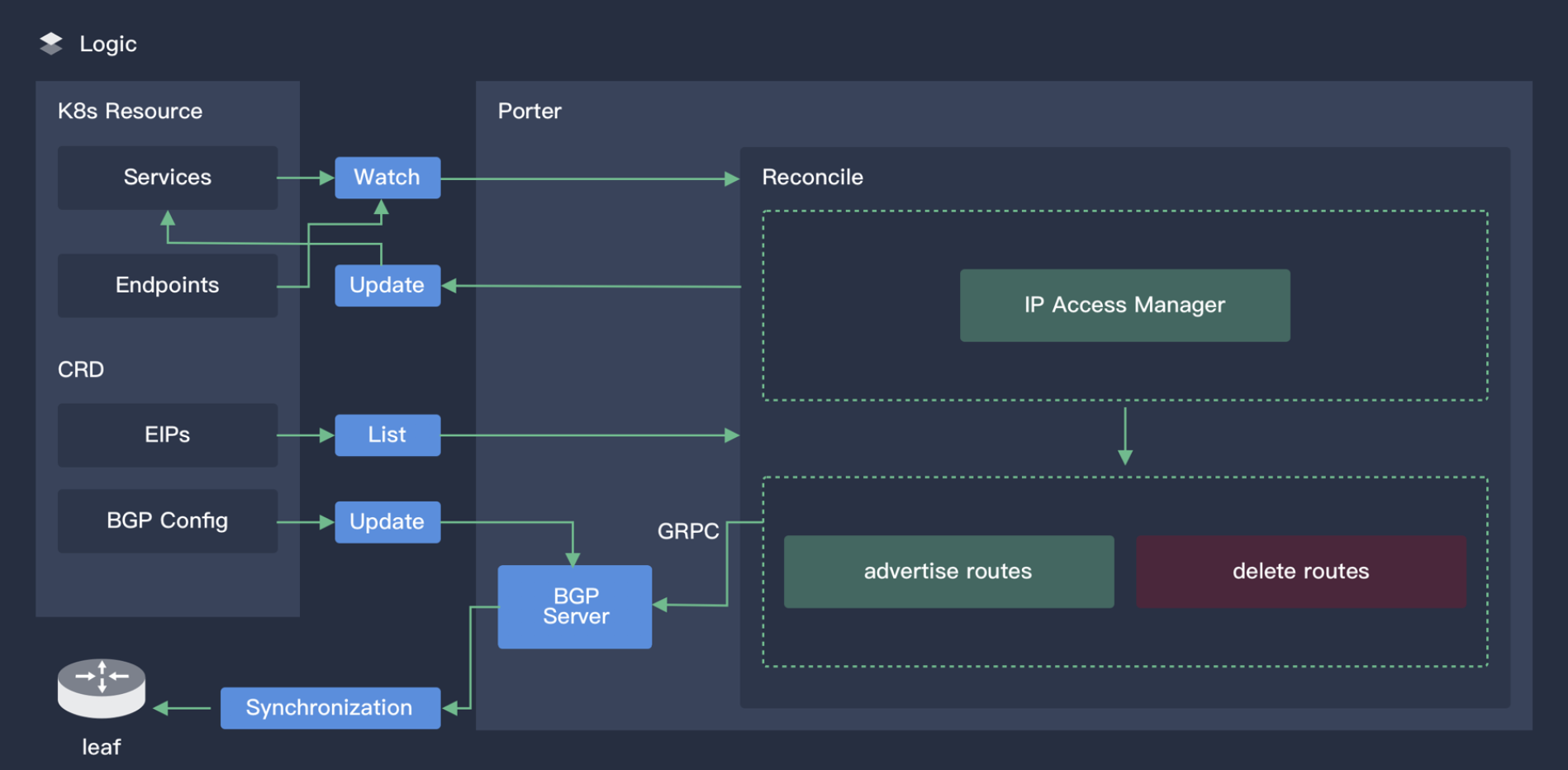
上图展示了 Porter 核心控制器的工作原理。
Agent 则是一个轻量级组件,用于监控 VIP 资源,增加 Iptables 规则让外部流量能够访问 VIP,默认情况下外部流量访问 VIP 会被内核中的 Forward 表 Drop 掉
面向云原生的设计
Porter 中的所有资源都是 CRD,包括 VIP、BGPPeer、BGPConfig 等。对于习惯 Kubectl 的用户使用 Porter 将非常友好。对于想定制 Porter 的高级用户,也可以直接调用 Kubernetes API 来二次开发。Porter 的核心控制器很快就会支持 HA,保证 Porter 的高可用性。
使用注意事项
用户访问 VIP 的流量会通过 BGP 到达 Kubernetes 集群中的某一个节点,因为 Porter 广播路由的路也是node而不是具体的 Pod IP,Pod IP 外部不可访问,后续 Node 到 Pod 的路由是由 kube-proxy 维护的。如下图:
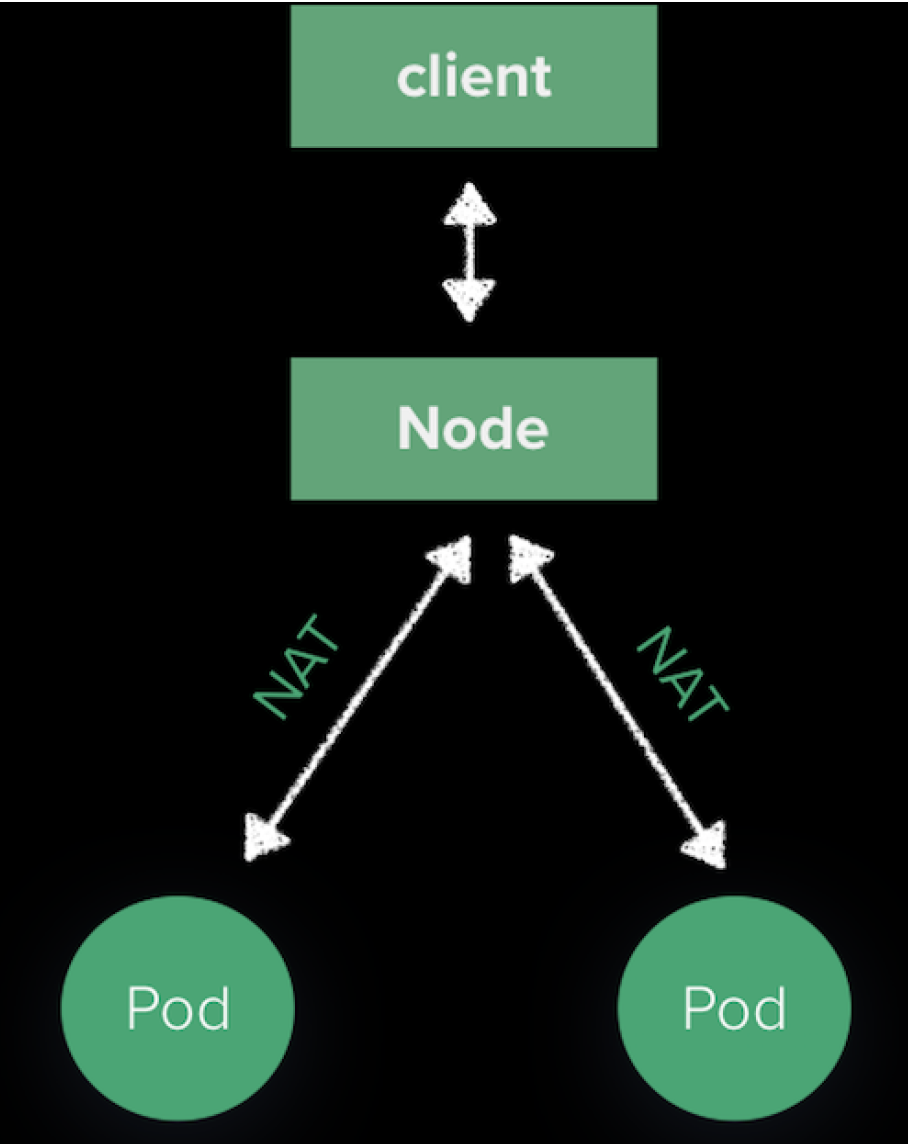
流量被 SNAT 之后随机发送给某一个 Pod。由于 Porter 会根据 Service Endpoints 的变化动态调整路由,确保下一跳的 Node 节点一定有 Pod 存在,所以我们可以更改 kube-proxy 这一个默认行为。在 Service 上设置 ExternalTrafficPolicy=local,达到下面的效果:
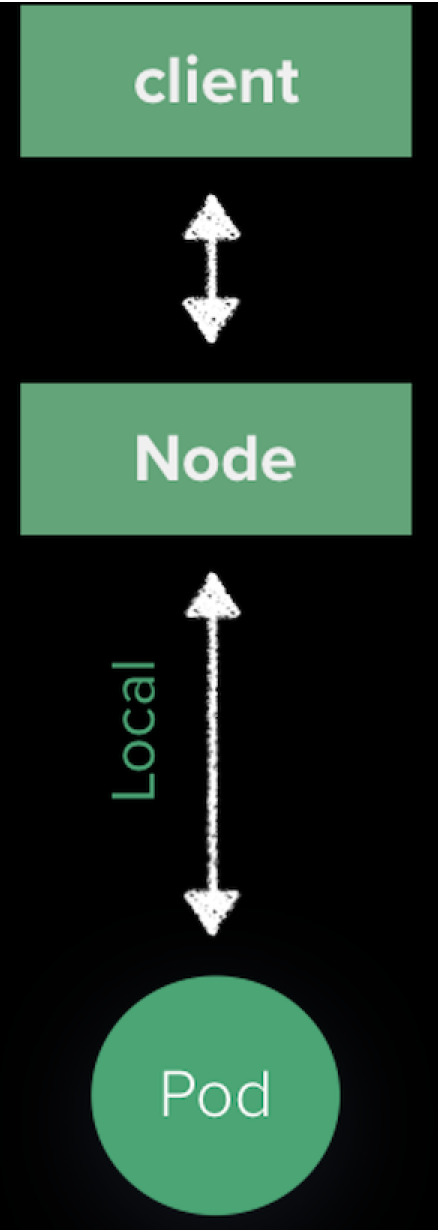
这样做有两个好处:
- SourceIP 不会 NAT
- 流量直接走本地,网络路径少一跳
未来计划
- 支持其他简单路由协议
- 更加方便的 VIP 管理
- BGP 的 Policy 支持
- 在 Kubesphere 集成,提供 Porter UI
相关资源
目录