












Log Query
The logs of applications and systems can help you better understand what is happening inside your cluster and workloads. The logs are particularly useful for debugging problems and monitoring cluster activities. KubeSphere provides a powerful and easy-to-use logging system which offers users the capabilities of log collection, query and management from the perspective of tenants. The tenant-based logging system is much more useful than Kibana since different tenants can only view their own logs, leading to better security. Moreover, the KubeSphere logging system filters out some redundant information so that tenants can only focus on logs that are useful to them.
This tutorial demonstrates how to use the log query function, including the interface, search parameters and details pages.
Prerequisites
You need to enable the KubeSphere Logging System.
Enter the Log Query Interface
-
The log query function is available for all users. Log in to the console with any account, hover over
 in the lower-right corner and select Log Search.
in the lower-right corner and select Log Search. -
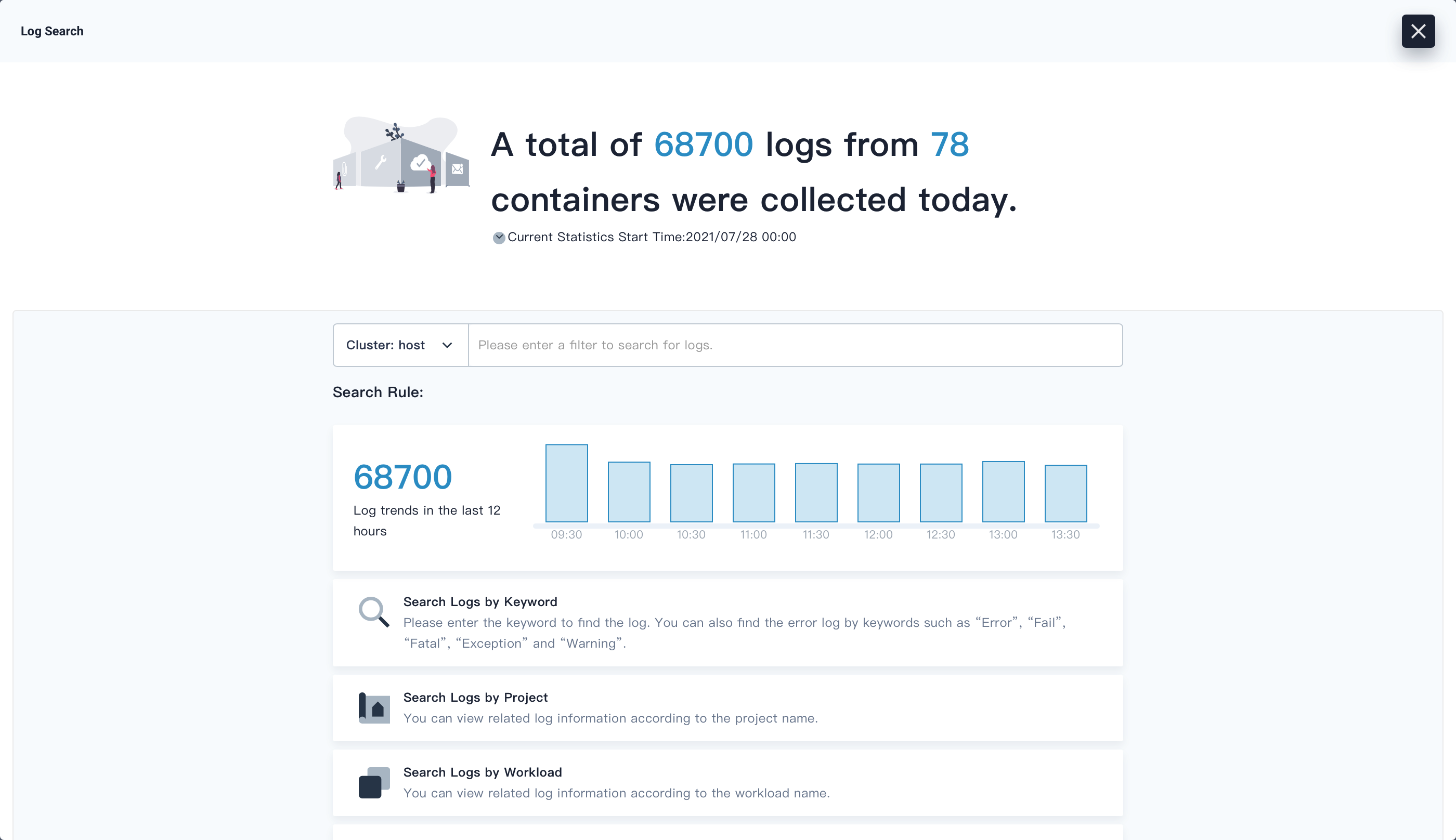
In the displayed dialog box, you can see a time histogram of log numbers, a cluster selection drop-down list and a log search box.
Note
-
KubeSphere supports log queries on each cluster separately if you have enabled the multi-cluster feature. You can click
 on the left of the search box and select a target cluster.
on the left of the search box and select a target cluster. -
KubeSphere stores logs for last seven days by default.
-
-
You can click the search box and enter a condition to search for logs by keyword, project, workload, Pod, container, or time range (for example, use
Time Range:Last 10 minutesto search for logs within the last 10 minutes). Alternatively, click on the bars in the time histogram, and KubeSphere will use the time range of that bar for log queries.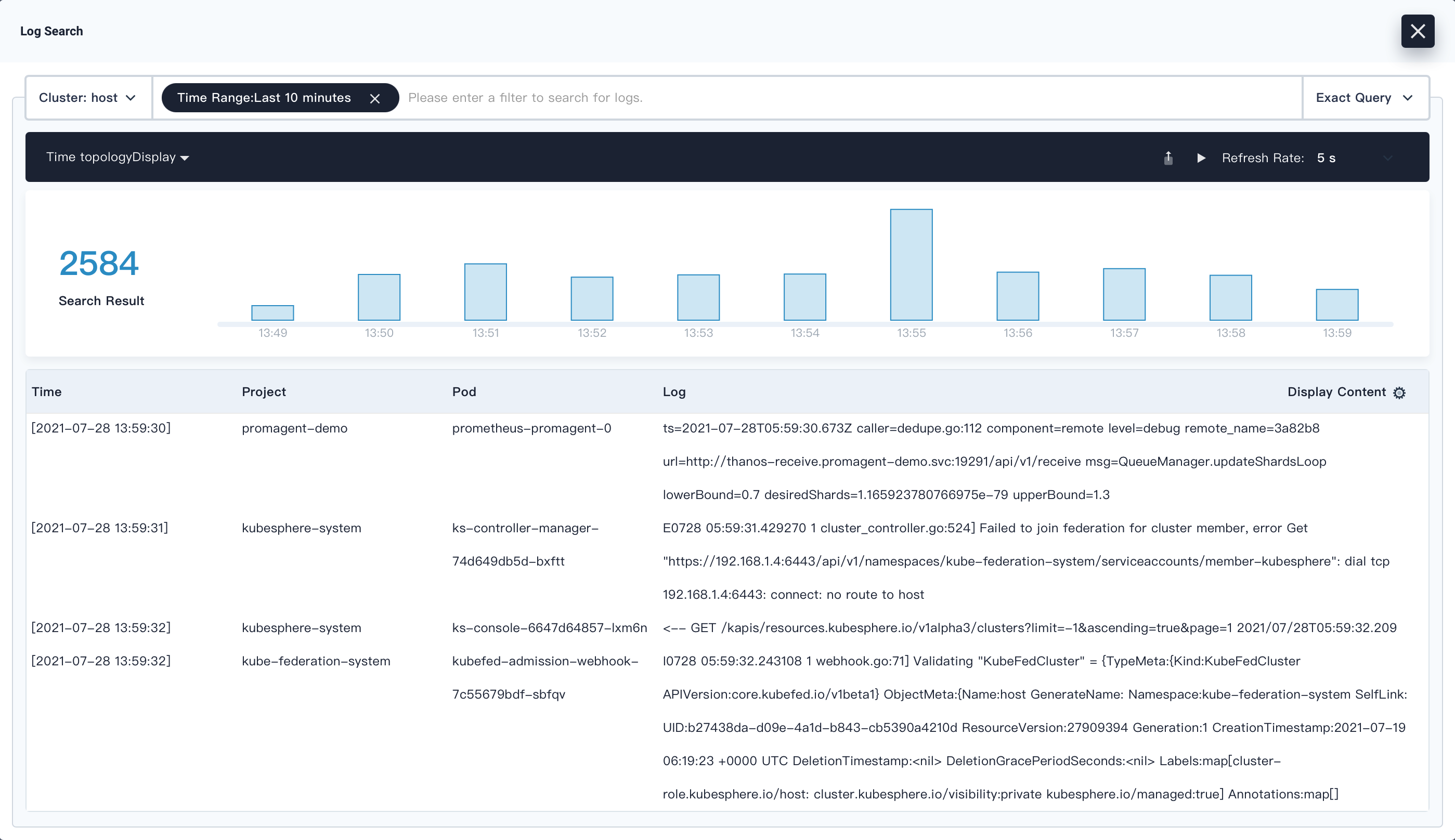
Note
- The keyword field supports the query of keyword combinations. For example, you can use
Error,Fail,Fatal,Exception, andWarningtogether to query all the exception logs. - The keyword field supports exact query and fuzzy query. The fuzzy query provides case-insensitive fuzzy matching and retrieval of full terms by the first half of a word or phrase based on the ElasticSearch segmentation rules. For example, you can retrieve the logs containing
node_cpu_totalby searching the keywordnode_cpuinstead of the keywordcpu. - Each cluster has its own log retention period which can be set separately. You can modify it in
ClusterConfiguration. For more information, see KubeSphere Logging System.
- The keyword field supports the query of keyword combinations. For example, you can use
Use Search Parameters
-
You can enter multiple conditions to narrow down your search results.
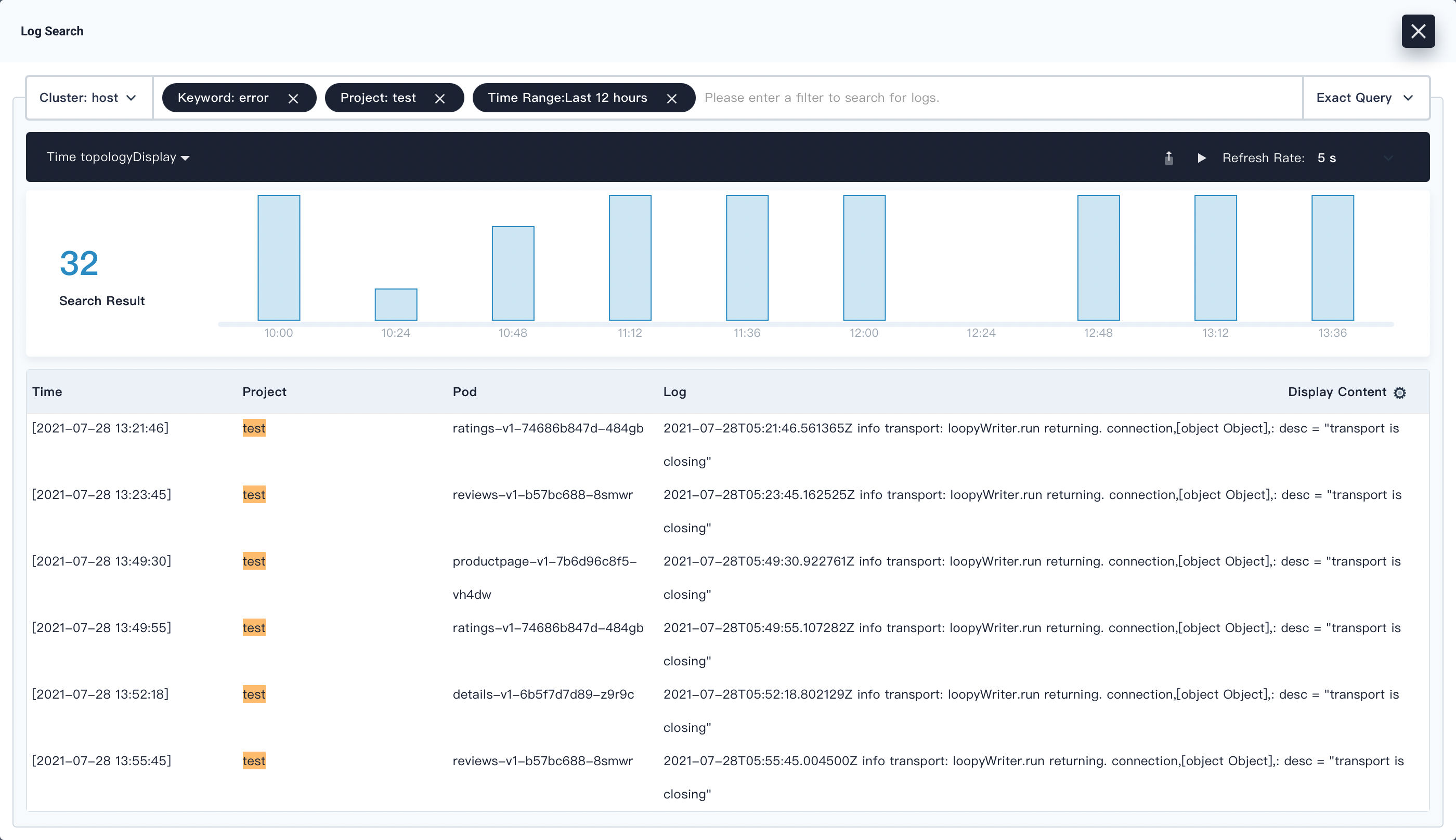
-
Click any one of the results from the list. Drill into its details page and inspect the log from this Pod, including the complete context on the right. It is convenient for developers in terms of debugging and analyzing.
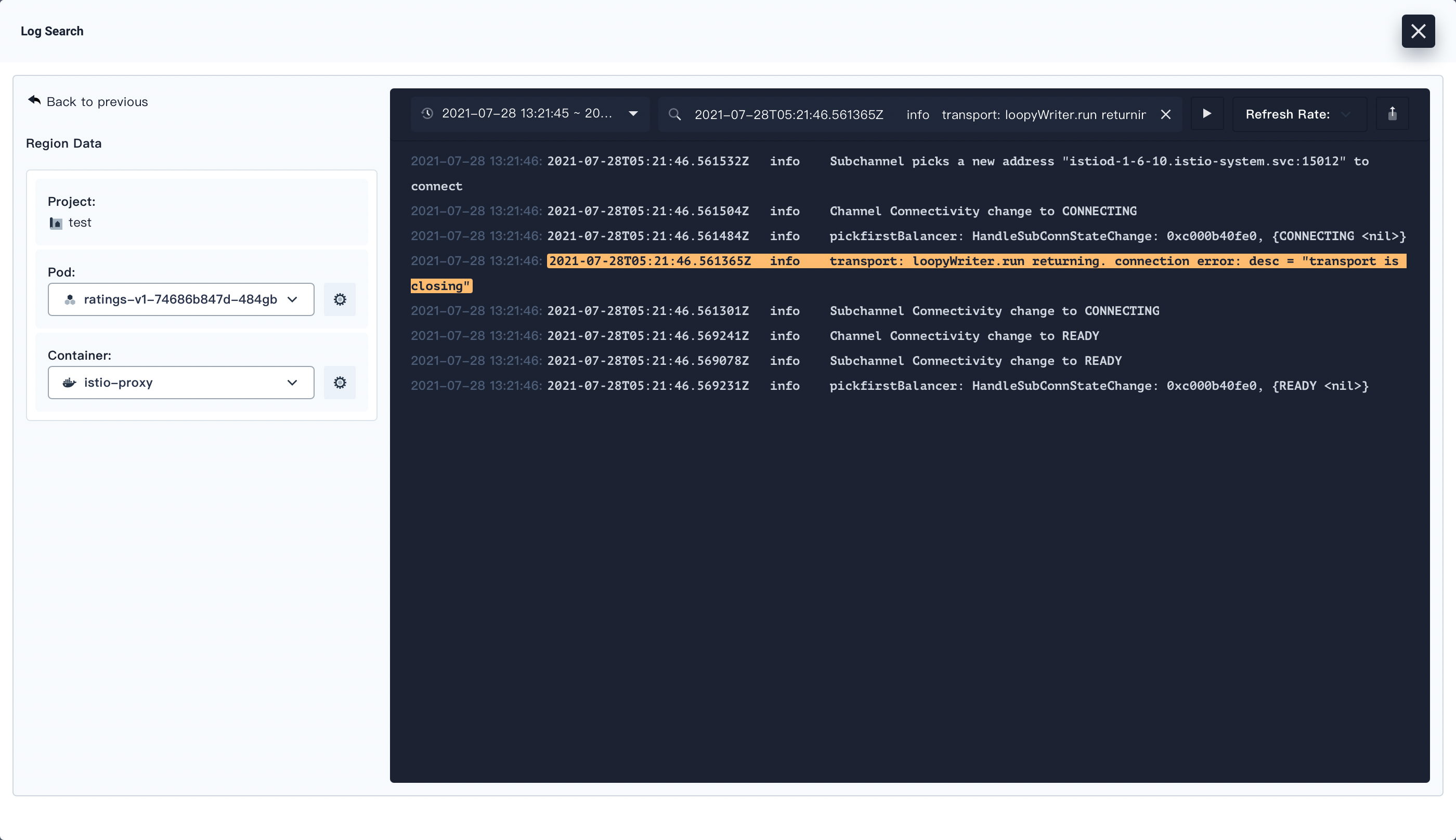
Note
- The log query interface supports dynamic refreshing with 5s, 10s, or 15s.
- You can click
 in the upper-right corner to export logs to a local file for further analysis.
in the upper-right corner to export logs to a local file for further analysis.
-
In the left panel, you can click
to switch between Pods and inspect its containers within the same project. In this case, you can detect if any abnormal Pods affect other Pods.
Drill into the Details Page
In the left panel, you can click ![]() to view the Pod details page or container details page.
to view the Pod details page or container details page.
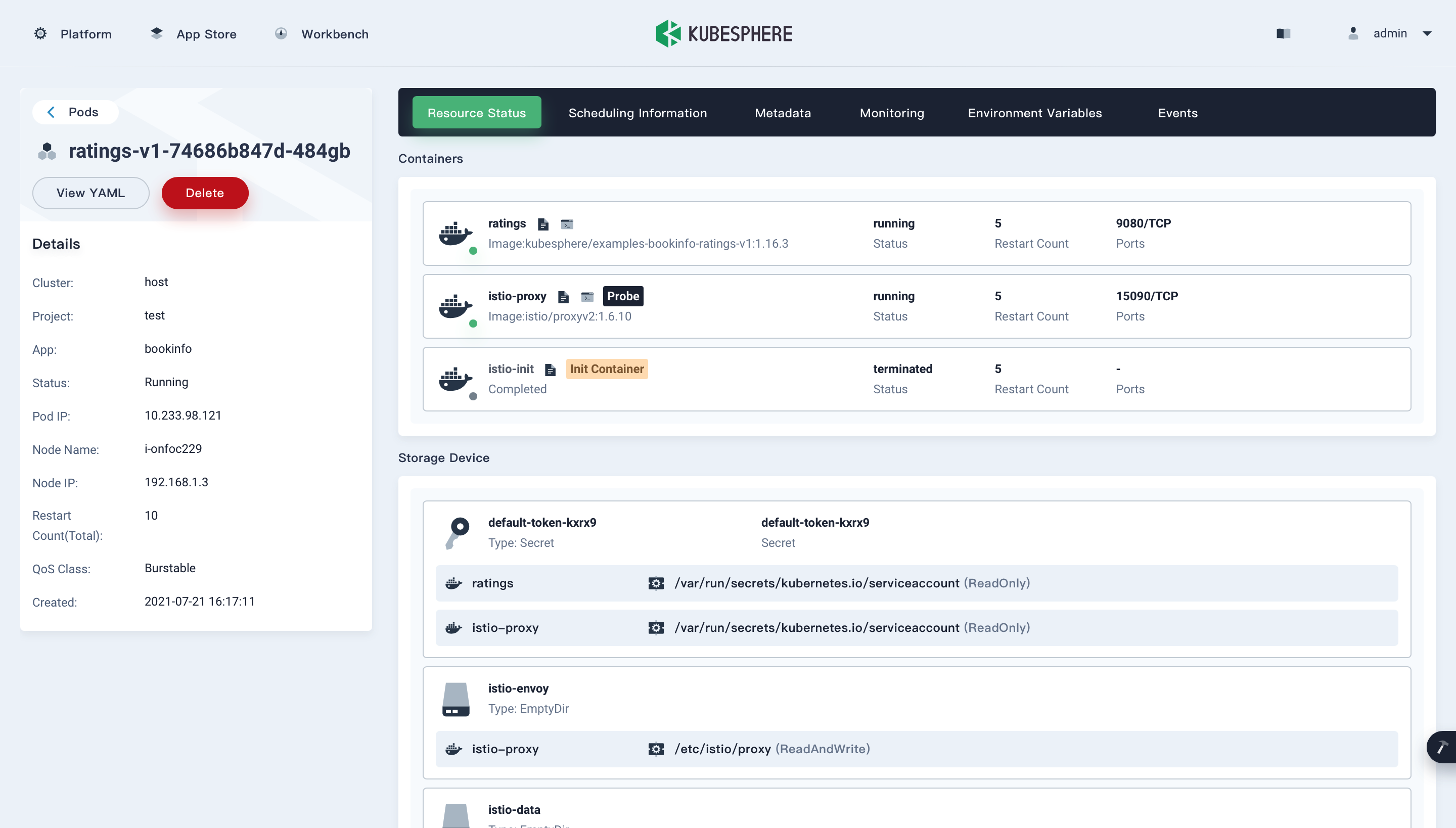
The following figure shows the Pod details page:
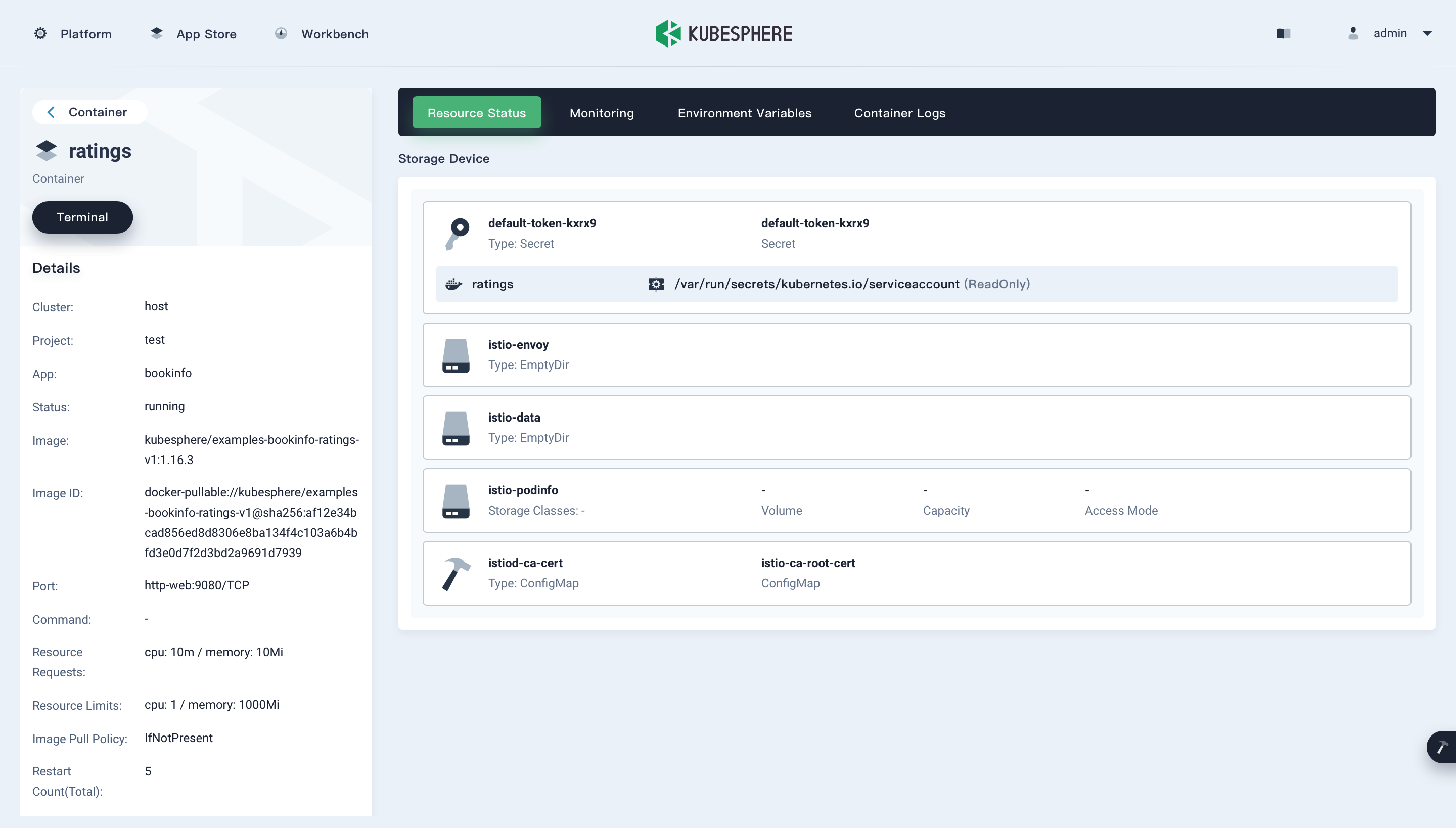
The following figure shows the container details page. You can click Terminal in the upper-left corner to open the terminal and debug the container.
Feedback
Was this page Helpful?
 Previous
Previous

What’s on this Page